生成AIの業務活用が加速する中、大規模言語モデル(LLM)の「ハルシネーション(幻覚)」問題が企業導入の障壁となっています。RAG(Retrieval-Augmented Generation:検索拡張生成)は、外部の知識ベースから関連情報を検索し、LLMの回答精度を飛躍的に向上させる技術です。本記事では、RAGの基本的な仕組みから、金融機関をはじめとする企業での導入手順、最新のGraph RAGやAgentic RAGまで、実務経験に基づいて徹底解説します。
RAG(検索拡張生成)とは
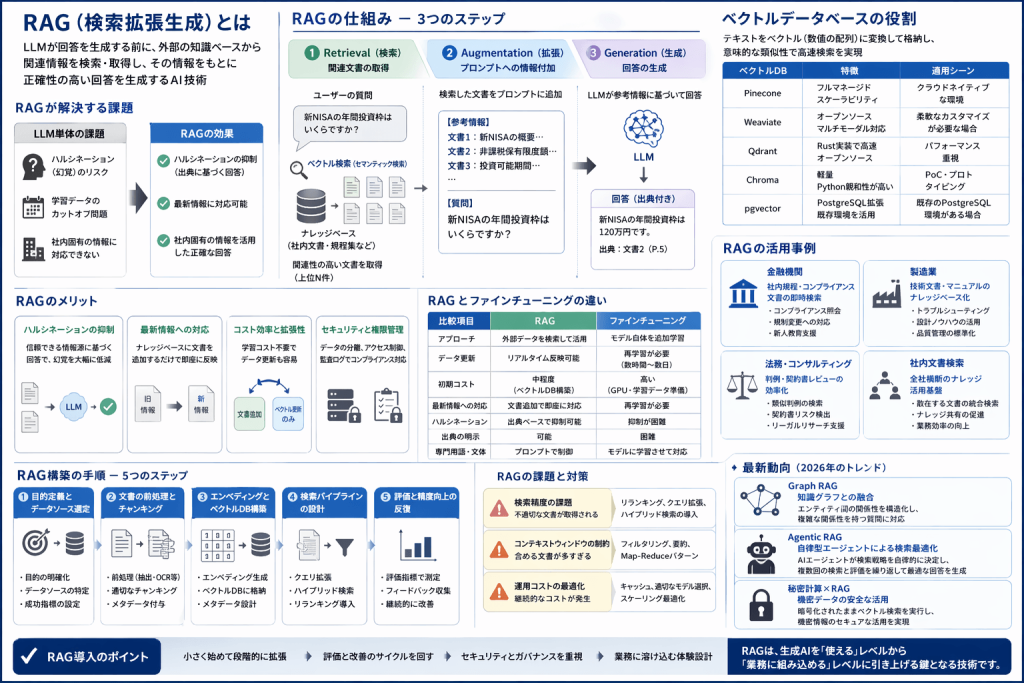
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、LLMが回答を生成する前に外部の知識ベースから関連情報を検索・取得し、その情報をもとに正確性の高い回答を生成するAI技術です。
RAGが注目される背景
ChatGPTの登場以降、企業における生成AIの活用は急速に広がりました。しかし、LLMを業務で利用する際に避けて通れない課題があります。それが「ハルシネーション(幻覚)」です。
ハルシネーションとは、LLMが事実に基づかない情報をもっともらしく生成してしまう現象です。一般的な会話では許容できる場合もありますが、金融機関の規制対応や契約書レビュー、医療判断の支援など、正確性が求められる業務では致命的な問題となります。
実際のプロジェクトでは、「社内の規程集を参照して回答してほしい」「最新の金融庁ガイドラインに基づいた回答が欲しい」といった要望が多く寄せられます。しかし、LLM単体では学習データに含まれない社内固有の情報には対応できず、また学習データのカットオフ以降の最新情報も把握していません。
RAGはこの課題を解決するために考案された技術です。2020年にMeta AI(旧Facebook AI Research)の研究チームが発表した論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」がRAGの概念を提唱し、以降急速に発展してきました。
RAGの基本的な定義
RAGを一言で表すと、「検索してから生成する」仕組みです。従来のLLMが自身の学習データ(パラメータに記憶された知識)のみで回答を生成するのに対し、RAGは回答生成の前に外部のデータソースから関連情報を検索し、その情報をコンテキスト(文脈)としてLLMに渡します。
これにより、LLMは自身が学習していない最新情報や社内固有の情報についても、検索された文書に基づいた正確な回答を生成できるようになります。
RAGの仕組み — 3つのステップで理解する
RAGのアーキテクチャは、大きく3つのステップで構成されています。それぞれの段階で何が行われているのかを詳しく見ていきましょう。
Step 1 — Retrieval(検索):関連文書の取得
RAGの最初のステップは、ユーザーの質問(クエリ)に関連する文書を外部のデータソースから検索することです。
具体的には、以下のプロセスが実行されます。
- ユーザーの質問文をエンベディングモデルによってベクトル(数値の配列)に変換する
- 事前にベクトル化して格納しておいた文書群(ナレッジベース)の中から、質問ベクトルに類似したベクトルを持つ文書チャンクを検索する
- 類似度の高い上位N件の文書チャンクを取得する
この検索には「セマンティック検索(意味的検索)」が用いられます。キーワードの完全一致ではなく、文章の意味的な類似性に基づいて検索するため、表現が異なっていても内容的に関連する文書を取得できる点が特徴です。
Step 2 — Augmentation(拡張):プロンプトへの情報付加
検索で取得した関連文書を、ユーザーの質問と組み合わせてプロンプト(LLMへの入力)を構築します。
典型的なプロンプトの構造は以下のようになります。
以下の参考情報に基づいて質問に回答してください。
参考情報に記載がない内容については「情報がありません」と回答してください。
【参考情報】
{検索で取得した文書チャンク1}
{検索で取得した文書チャンク2}
{検索で取得した文書チャンク3}
【質問】
{ユーザーの質問}このように、検索結果をプロンプトに付加(Augment)することで、LLMは外部の知識に基づいた回答を生成できるようになります。プロンプトの設計(プロンプトエンジニアリング)はRAGの精度に大きく影響する重要な要素です。
Step 3 — Generation(生成):回答の生成
拡張されたプロンプトをLLMに入力し、回答を生成します。LLMはプロンプトに含まれる参考情報を文脈として考慮しながら、ユーザーの質問に対する回答を生成します。
ここでのポイントは、LLMが自身の事前学習知識だけでなく、検索された最新の文書情報を優先的に参照して回答する点です。適切なプロンプト設計により、「参考情報に基づいて回答する」という指示をLLMに与えることで、ハルシネーションのリスクを大幅に低減できます。
ベクトルデータベースの役割
RAGの検索ステップを支える重要な基盤技術が「ベクトルデータベース」です。
ベクトルデータベースとは、テキストや画像などのデータをベクトル(高次元の数値配列)として格納し、ベクトル間の類似度検索を高速に実行できるデータベースです。
代表的なベクトルデータベースには以下のものがあります。
| ベクトルDB | 特徴 | 適用シーン |
|---|---|---|
| Pinecone | フルマネージド、スケーラビリティ | クラウドネイティブな環境 |
| Weaviate | オープンソース、マルチモーダル対応 | 柔軟なカスタマイズが必要な場合 |
| Qdrant | Rust実装で高速、オープンソース | パフォーマンス重視 |
| Chroma | 軽量、Python親和性が高い | PoC・プロトタイピング |
| pgvector | PostgreSQL拡張 | 既存のPostgreSQL環境がある場合 |
金融機関での導入では、データの所在管理やセキュリティ要件の観点から、オンプレミスまたはプライベートクラウドで運用可能なオープンソースのベクトルデータベースが選択されるケースが多く見られます。
RAGのメリットと導入効果
ハルシネーション(幻覚)の抑制
RAGの最大のメリットは、LLMのハルシネーションを大幅に抑制できる点です。外部の信頼できるデータソースから検索した情報に基づいて回答を生成するため、事実に基づかない情報の生成リスクが低減されます。
さらに、回答の根拠となった文書(出典)を明示できるため、利用者は回答の信頼性を自ら検証することが可能です。導入時に直面した課題として、この「出典の透明性」が金融機関のコンプライアンス部門から最も高く評価されるポイントでした。
最新情報への対応力
LLMの学習データにはカットオフ日があり、それ以降の情報は含まれていません。RAGでは、ナレッジベースに最新の文書を追加するだけで、LLMの再学習なしに最新情報に基づいた回答が可能になります。
金融業界では規制の変更が頻繁に発生するため、この「情報の鮮度」は極めて重要です。例えば、金融庁のガイドライン改訂があった場合、該当文書をナレッジベースに追加するだけで即座に対応できます。
コスト効率とスケーラビリティ
ファインチューニングと比較して、RAGは以下の点でコスト効率に優れています。
- 学習コストが不要: ファインチューニングではGPUを使った追加学習が必要ですが、RAGではデータのベクトル化のみで完了
- データ更新が容易: 新しい文書の追加や既存文書の更新が、ベクトルの再計算のみで完了
- モデル非依存: LLMのバージョンアップやモデル変更時にも、ナレッジベースをそのまま利用可能
セキュリティと権限管理
RAGはセキュリティの観点からも優れた特性を持っています。
- データの分離: 社内文書はベクトルデータベースに保存され、LLMプロバイダーに送信される情報を制御できる
- アクセス制御: ベクトルデータベースのメタデータフィルタリングにより、ユーザーの権限に応じて参照可能な文書を制限できる
- 監査性: どの文書を参照して回答が生成されたかのログを記録でき、コンプライアンス要件を満たしやすい
RAGとファインチューニングの違い
LLMをカスタマイズする手法として、RAGとファインチューニングはよく比較されます。両者の特性を正しく理解し、適切に使い分けることが重要です。
ファインチューニングとは
ファインチューニングとは、既存のLLMに追加のデータセットを用いて再学習を行い、特定のタスクやドメインに特化させる手法です。モデルのパラメータ自体が更新されるため、特定分野の表現力や専門用語の理解が向上します。
RAG vs ファインチューニング比較表
| 比較項目 | RAG | ファインチューニング |
|---|---|---|
| アプローチ | 外部データを検索して活用 | モデル自体を追加学習 |
| データ更新 | リアルタイム反映可能 | 再学習が必要(数時間〜数日) |
| 初期コスト | 中程度(ベクトルDB構築) | 高い(GPU・学習データ準備) |
| 運用コスト | API利用料 + ベクトルDB運用 | モデルホスティング費用 |
| 正確性 | 出典明示が可能 | モデルの内部知識に依存 |
| 最新情報への対応 | 文書追加で即座に対応 | 再学習が必要 |
| ハルシネーション | 出典ベースで抑制可能 | 抑制が困難 |
| 専門用語・文体 | プロンプトで制御 | モデルに学習させて対応 |
使い分けの判断基準
実際のプロジェクトでは、以下の判断基準で選択することを推奨しています。
RAGが適しているケース:
- 社内文書やナレッジベースに基づく回答が必要
- データの更新頻度が高い
- 回答の根拠(出典)の提示が求められる
- 初期コストを抑えたい
ファインチューニングが適しているケース:
- 特定ドメインの専門的な文体・表現が必要
- 応答速度を最優先にしたい(検索ステップを省略できるため)
- 学習データが固定的で更新頻度が低い
多くの企業ユースケースでは、RAGが第一選択肢となります。ファインチューニングとRAGを併用する「ハイブリッドアプローチ」も有効です。
RAGの活用事例 — 業界別導入パターン
金融機関 — 社内規程・コンプライアンス文書の即時検索
金融機関では、膨大な社内規程、コンプライアンスマニュアル、金融庁ガイドラインなどの文書を参照する業務が日常的に発生します。RAGを導入することで、担当者が自然言語で質問するだけで、関連する規程やガイドラインの該当箇所を即座に取得し、正確な回答を得ることが可能になります。
実際のプロジェクトでは、以下のようなユースケースでRAGが活用されています。
- コンプライアンス照会の自動化: 営業担当者からの「この取引は規程上問題ないか?」という照会に対し、関連する社内規程を検索して回答
- 規制変更への対応: 金融庁のガイドライン改訂時に、社内規程のどの部分が影響を受けるかを自動分析
- 新人教育支援: 複雑な業務マニュアルの中から、新人の質問に応じた箇所を検索して解説
製造業 — 技術文書・マニュアルのナレッジベース化
製造業では、設計仕様書、作業手順書、品質管理マニュアルなどの技術文書が大量に存在します。RAGにより、ベテランエンジニアの退職によるナレッジ喪失のリスクを軽減し、過去の知見を活用した迅速な問題解決が可能になります。
法務・コンサルティング — 判例・契約書レビューの効率化
法務分野では、過去の判例、契約書テンプレート、法令データベースなどをナレッジベースとして、契約書のリスク箇所の自動検出や類似判例の検索にRAGが活用されています。
社内文書検索 — 全社横断のナレッジ活用基盤
部門を横断した社内ナレッジの活用は、多くの企業が抱える課題です。RAGを活用した社内文書検索システムにより、イントラネット、SharePoint、Confluenceなどに散在するドキュメントを統合的に検索し、必要な情報に素早くアクセスできる環境を構築できます。
RAG構築の手順 — 5つのステップ
企業でRAGシステムを構築する際の実践的な手順を、5つのステップに分けて解説します。
Step 1 — 目的定義とデータソース選定
RAG導入の成否を分けるのが、この最初のステップです。
- 目的の明確化: 「何を」「誰が」「どのような場面で」利用するのかを具体化する
- データソースの特定: 対象となる文書の種類、フォーマット(PDF、Word、HTML等)、量、更新頻度を把握する
- 成功指標の設定: 回答精度、応答速度、ユーザー満足度などのKPIを事前に定義する
導入時に直面した課題として、「対象文書の範囲を広げすぎてノイズが増える」ケースが多く見られます。まずは限定的なスコープで開始し、段階的に拡張するアプローチを推奨します。
Step 2 — 文書の前処理とチャンキング
RAGの精度に大きく影響するのが、文書の前処理とチャンキング(分割)戦略です。
- 前処理: PDF抽出、OCR処理、メタデータ付与、不要な装飾やヘッダー・フッターの除去
- チャンキング: 文書を適切なサイズに分割する。一般的には200〜500トークン程度が目安だが、文書の性質によって最適なサイズは異なる
- チャンキング戦略: 固定長分割、セマンティック分割(意味の区切りで分割)、階層的分割(見出し構造を活用)など
金融機関の文書では、条文番号や参照関係が重要なため、階層的分割と条文単位の分割を組み合わせたカスタムチャンキングが有効です。
Step 3 — エンベディングとベクトルデータベース構築
チャンク化した文書をエンベディングモデルでベクトルに変換し、ベクトルデータベースに格納します。
- エンベディングモデルの選択: OpenAI text-embedding-3-small/large、Cohere Embed、日本語に強いモデル(multilingual-e5-large等)
- ベクトルデータベースの選択: 前述の比較表を参考に、セキュリティ要件、スケーラビリティ、運用コストを考慮して選定
- メタデータの設計: 文書の出典、作成日、カテゴリ、アクセス権限などをメタデータとして格納し、検索時のフィルタリングに活用
Step 4 — 検索パイプラインの設計
ユーザーの質問から最適な回答を生成するまでのパイプラインを設計します。
- クエリ拡張: ユーザーの質問文をそのまま検索するだけでなく、同義語や関連キーワードを追加して検索精度を向上
- ハイブリッド検索: ベクトル検索(セマンティック検索)とキーワード検索(BM25等)を組み合わせて、検索漏れを防止
- リランキング: 初期検索結果に対してクロスエンコーダなどのリランキングモデルを適用し、最も関連性の高い文書チャンクを上位に再配置
Step 5 — 評価と精度向上の反復
RAGシステムの精度は、継続的な評価と改善によって向上させます。
- 評価指標: 回答精度(Accuracy)、適合率(Precision)、再現率(Recall)、回答の忠実性(Faithfulness)
- RAGAS: RAGの評価フレームワーク。回答の関連性、忠実性、コンテキストの適切さを自動評価
- フィードバックループ: ユーザーからのフィードバックを収集し、チャンキング戦略、プロンプト設計、検索パラメータを継続的に改善
RAGの課題と対策
検索精度の課題とリランキング
RAGの回答品質は、検索ステップの精度に大きく依存します。検索が不適切な文書を取得した場合、LLMは誤った情報に基づいて回答を生成してしまいます。
対策:
- リランキングモデルの導入(Cohere Rerank、BGE-rerankerなど)
- クエリ拡張によるLLMベースの検索クエリ生成
- ハイブリッド検索(ベクトル検索+キーワード検索)の併用
コンテキストウィンドウの制約と対策
LLMには入力トークン数の上限(コンテキストウィンドウ)があります。検索で取得した文書チャンクが多すぎると、すべてをプロンプトに含めることができません。
対策:
- 検索結果の適切なフィルタリングとランキング
- 文書チャンクの要約(サマリゼーション)
- Map-Reduceパターン(文書群を個別に処理し、結果を統合)
運用コストの最適化
RAGの運用では、LLMのAPI利用料、ベクトルデータベースの運用費用、エンベディング生成のコストが継続的に発生します。
対策:
- キャッシュ機構の導入(類似クエリへの回答をキャッシュ)
- エンベディングモデルの適切な選択(精度とコストのバランス)
- 利用頻度に応じたインフラのスケーリング
RAGの最新動向 — 2026年のトレンド
Graph RAG — 知識グラフとの融合
Graph RAGは、従来のフラットな文書チャンク検索に加えて、知識グラフ(ナレッジグラフ)を活用するアプローチです。エンティティ(人物、企業、規制など)間の関係性を構造化して保持するため、「A社の子会社であるB社に適用される規制は?」といった、関係性を辿る複雑な質問にも対応できます。
金融機関では、企業グループ構造の把握、規制間の依存関係の可視化、取引ネットワークの分析などに応用が期待されています。
Graph RAGの実装には、Neo4jやAmazon Neptuneなどのグラフデータベースとベクトルデータベースを組み合わせたハイブリッドアーキテクチャが用いられます。グラフニューラルネットワーク(GNN)の技術を活用することで、グラフ構造からのより高度な情報検索も可能になりつつあります。
※関連記事: グラフニューラルネットワーク(GNN)とは?
Agentic RAG — 自律型エージェントによる検索最適化
Agentic RAGは、AIエージェントが検索プロセス全体を自律的に制御するアーキテクチャです。従来のRAGが「1回の検索→1回の生成」という固定的なパイプラインであるのに対し、Agentic RAGではエージェントが以下のプロセスを自律的に実行します。
- ユーザーの質問を分析し、最適な検索戦略を決定
- 複数のデータソースに対して検索を実行
- 検索結果の品質を評価し、不十分な場合は検索クエリを修正して再検索
- 十分な情報が集まった時点で、統合的な回答を生成
金融機関のコンプライアンス業務では、複数の規制文書を横断的に調査する必要があるため、Agentic RAGの自律的な検索能力が大きな価値を発揮します。
ただし、エージェントの自律的な判断にはガードレール(安全装置)の設計が不可欠です。特に金融領域では、エージェントが参照してよい文書の範囲を厳密に制限する必要があります。
秘密計算×RAG — 機密データの安全な活用
秘密計算技術とRAGを組み合わせることで、機密データを復号化せずにベクトル検索を行う取り組みが進んでいます。準同型暗号ベースのベクトル検索や、TEE(Trusted Execution Environment)上でのRAG実行など、複数のアプローチが研究・実用化されつつあります。
特に金融機関間でのセキュアなナレッジ共有(例:AML対策での情報共有)や、クロスボーダー取引における各国規制文書の安全な横断検索など、従来は実現困難だったユースケースへの応用が期待されています。
※関連記事: 秘密計算とは?仕組みから活用事例まで徹底解説
まとめ
本記事では、RAG(検索拡張生成)の基本的な仕組みから企業での導入手順、最新のトレンドまでを解説しました。
RAGの要点:
- RAGは「検索→拡張→生成」の3ステップで、LLMの回答精度を向上させる技術
- ハルシネーションの抑制、最新情報への対応、コスト効率に優れる
- ファインチューニングと比較して、多くの企業ユースケースで第一選択肢となる
- 金融機関では、コンプライアンス文書検索や規制対応に大きな価値を発揮
- Graph RAG、Agentic RAGなどの発展により、より高度な活用が可能に
RAGは、生成AIを「使える」レベルから「業務に組み込める」レベルに引き上げる鍵となる技術です。特に金融機関をはじめとする、正確性とセキュリティが求められる業界において、RAGの導入は競争優位性を確保するための重要な戦略となるでしょう。
RAG導入のご相談はテンファイブへ
テンファイブは、20年以上にわたる金融システム開発の実績と、最新のAIソリューション技術を併せ持つSES企業です。金融機関特有のセキュリティ要件やコンプライアンス対応を熟知したエンジニアが、RAGシステムの設計・構築・運用までをトータルでサポートいたします。
- 金融機関向けRAGシステムの設計・構築
- 秘密計算技術を活用したセキュアなRAG基盤の提案
- 既存システムとのRAG統合コンサルティング
- PoCから本番運用までの段階的導入支援
RAG導入に関するご相談は、お気軽にお問い合わせください。



