「データは21世紀の石油」と言われる一方で、金融業界ではデータの取り扱いに厳格な規制が課されています。複数の金融機関が保有するデータを集約してAIモデルを構築できれば理想的ですが、個人情報保護法やGDPRの制約がそれを阻みます。この課題を解決する技術が「連合学習(Federated Learning)」です。
本記事では、連合学習の仕組みから金融分野での活用事例、秘密計算との違い、導入のポイントまでを体系的に解説します。
> 関連記事: プライバシー保護技術についてさらに詳しく知りたい方は「秘密計算とは?仕組みから活用事例まで徹底解説」もあわせてご覧ください。
連合学習とは
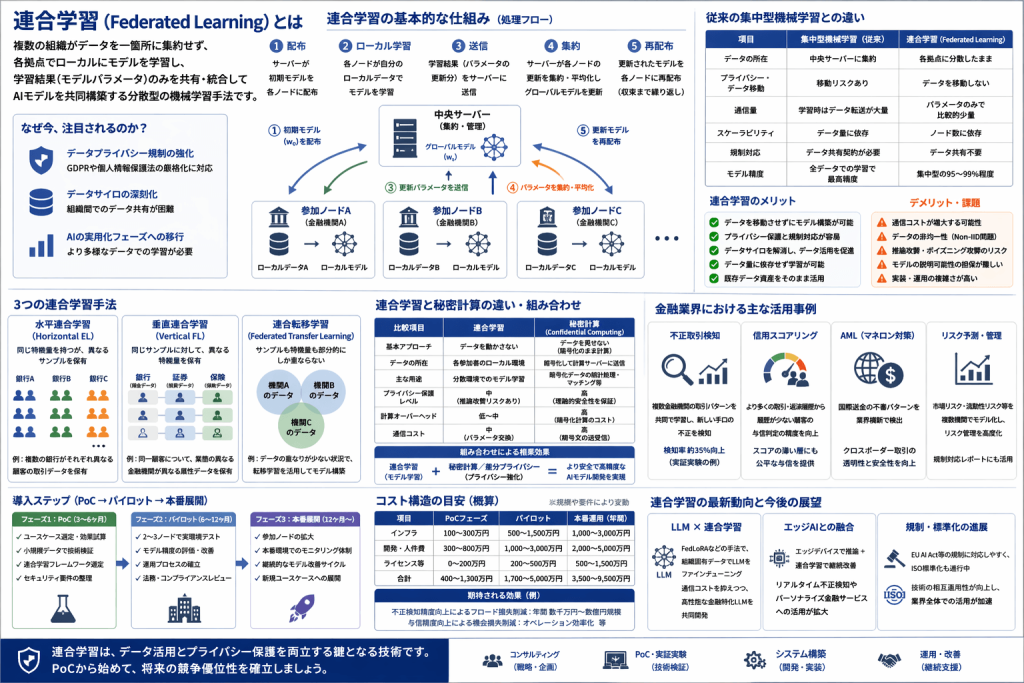
> 連合学習(Federated Learning)とは、複数の端末や組織がデータを一箇所に集約せず、各拠点でローカルにモデルを学習し、学習結果のみを共有・統合してAIモデルを共同構築する分散型の機械学習手法です。
連合学習の基本概念と定義
連合学習は、2016年にGoogleの研究チームが提唱した機械学習のアプローチです。従来の機械学習では、学習に必要なデータをすべて中央サーバーに集約する必要がありました。しかし、連合学習ではデータを各端末や組織に置いたまま、モデルの学習結果(パラメータ)のみをやり取りします。
具体的には、以下のようなプロセスで学習が進みます。
- 中央サーバーが初期モデルを各参加ノードに配布する
- 各ノードが自分のローカルデータでモデルを学習する
- 学習結果(モデルパラメータの更新分)を中央サーバーに送信する
- 中央サーバーが各ノードの更新を集約(平均化等)し、グローバルモデルを更新する
- 更新されたグローバルモデルを各ノードに再配布する
- 2〜5を収束するまで繰り返す
この仕組みにより、元データを外部に出すことなく、複数組織のデータから学習した高精度なAIモデルを構築できます。
なぜ今「連合学習」が注目されるのか
連合学習が急速に注目を集めている背景には、3つの要因があります。
第一に、データプライバシー規制の強化です。 2018年のGDPR施行以降、世界各国で個人データの取り扱いに関する規制が厳格化しています。日本でも2022年の個人情報保護法改正により、データの越境移転や目的外利用に対する規制が強化されました。連合学習は、こうした規制環境の中でデータ活用を両立させる技術として期待されています。
第二に、データサイロの深刻化です。 企業のデジタル化が進む一方で、部門間・企業間でのデータ共有は依然として困難です。実際のプロジェクトでは、同じ銀行グループ内でもリテール部門と法人部門のデータ統合に数年を要するケースは珍しくありません。連合学習はデータを統合せずにAIモデルを構築できるため、データサイロ問題の現実的な解決策となります。
第三に、AI技術の実用化フェーズへの移行です。 多くの企業がAI導入のPoCフェーズを終え、本格的な運用段階に入っています。運用段階では、より多様なデータで学習したモデルの構築が求められますが、データの収集・集約には限界があります。連合学習は、既存のデータ資産をそのまま活用できる点で、AI実用化の加速に貢献します。
従来の集中型機械学習との違い
| 項目 | 集中型機械学習 | 連合学習 |
|---|---|---|
| データの所在 | 中央サーバーに集約 | 各拠点に分散したまま |
| プライバシー | データ移動リスクあり | データを移動しない |
| 通信量 | 学習時はデータ転送が大量 | パラメータのみで比較的少量 |
| スケーラビリティ | データ量に依存 | ノード数に依存 |
| 規制対応 | データ共有契約が必要 | データ共有不要 |
| モデル精度 | 全データでの学習で最高精度 | 集中型の95〜99%程度 |
連合学習の仕組み
連合学習の基本的な処理フロー
連合学習の最も基本的なアルゴリズムは、Googleが2017年に発表したFedAvg(Federated Averaging)です。FedAvgでは、各ノードが一定のエポック数だけローカルで学習を行い、その結果をサーバーで平均化して統合します。
処理フローをもう少し技術的に説明すると、以下のようになります。
- 初期化: サーバーがランダムに初期化されたモデルパラメータ w₀ を生成
- 配布: 各ノード k に現在のグローバルモデル wₜ を送信
- ローカル学習: 各ノードが自身のデータセット Dₖ でSGD(確率的勾配降下法)を実行し、ローカルモデル wₖ を更新
- 集約: サーバーがデータ量に応じた重み付き平均で各ノードのモデルを統合
- 反復: 2〜4をT回繰り返す
実際のプロジェクトでは、通信効率を高めるために勾配の圧縮(Gradient Compression)やモデルの量子化(Quantization)を組み合わせることが一般的です。
3つの連合学習手法
連合学習は、データの分割方法によって大きく3つに分類されます。
水平連合学習(Horizontal Federated Learning)
各参加者が同じ特徴量(カラム)を持つが、異なるサンプル(行)を保有するケースです。たとえば、複数の地方銀行がそれぞれ異なる顧客の預金・融資データを保有しているようなケースが該当します。最も一般的な連合学習の形態です。
垂直連合学習(Vertical Federated Learning)
各参加者が同じサンプル(同一人物)に対して異なる特徴量を持つケースです。たとえば、銀行が預金データを、証券会社が投資データを、保険会社が保険契約データを保有しており、同一顧客についてそれぞれ異なる属性を持っているようなケースです。金融機関間の連携では、この垂直型が特に重要です。
連合転移学習(Federated Transfer Learning)
参加者間でサンプルも特徴量も部分的にしか重ならないケースに適用されます。転移学習の手法を組み合わせることで、データの重なりが少ない状況でも効果的なモデル構築を可能にします。
分散学習との違い
連合学習と混同されやすい概念として「分散学習(Distributed Learning)」があります。両者の最大の違いは、目的と前提にあります。
分散学習は、大量のデータや計算を複数のマシンに分散させることで、学習を高速化することが主な目的です。データは自由にアクセスできる前提で、計算資源の効率化が狙いです。
一方、連合学習は、データのプライバシーを保護しながら複数の組織が協調的にモデルを構築することが目的です。データは各組織の管理下にあり、外部に出せない前提です。
連合学習のメリットとデメリット
メリット①:データを移動させずにモデル構築が可能
連合学習の最大のメリットは、元データを各組織の管理下に置いたまま、高精度なAIモデルを構築できることです。データの移動にはセキュリティリスク、通信コスト、法的手続きなど多くのハードルが伴いますが、連合学習ではこれらを回避できます。
導入時に直面した課題として多いのは、「本当にデータが外部に漏れないのか」という組織内の不安です。この点については、差分プライバシー(Differential Privacy)を組み合わせることで、数学的に保証されたプライバシー保護を実現できます。
メリット②:プライバシー保護と規制対応
金融業界においては、個人情報保護法、金融庁ガイドライン、FISC安全対策基準など、複数の規制に準拠する必要があります。連合学習は、データそのものを共有しないため、これらの規制への対応を大幅に簡素化できます。
特に、EUの金融機関と取引がある場合、GDPRのデータ越境移転規制への対応は大きな課題です。連合学習を活用すれば、EUのデータをEU域外に移転することなくモデルを構築できます。
メリット③:データサイロの解消
多くの金融機関が抱えるデータサイロ問題に対して、連合学習は「データを動かさずに価値を引き出す」という新しいアプローチを提供します。データ統合プロジェクトは通常、数年規模の大型プロジェクトになりますが、連合学習であれば比較的短期間で成果を出すことが可能です。
デメリットと課題
通信コスト: 学習ラウンドごとにモデルパラメータを各ノードとやり取りするため、参加ノード数やモデルサイズが大きくなると通信コストが増大します。特に大規模言語モデル(LLM)の連合学習では、この課題が顕著になります。
データの非均一性(Non-IID問題): 各参加者のデータ分布が異なる場合(Non-IID: Non-Independent and Identically Distributed)、モデルの収束が遅くなったり、精度が低下する可能性があります。金融業界では、各機関の顧客層が異なるため、この問題は特に深刻です。
セキュリティリスク: モデルパラメータから元データを推定する「推論攻撃」や、悪意のある参加者が不正なパラメータを送信する「ポイズニング攻撃」のリスクがあります。
モデルの説明可能性: 金融規制では、AIの判断根拠を説明することが求められます(説明可能AI / XAI)。連合学習で構築されたモデルの場合、各ノードのデータにアクセスできないため、説明性の担保がより困難になります。
連合学習と秘密計算の違い・組み合わせ
両技術の比較表
| 比較項目 | 連合学習 | 秘密計算 |
|---|---|---|
| 基本アプローチ | データを動かさない | データを見せない(暗号化のまま計算) |
| データの所在 | 各参加者のローカル環境 | 暗号化して計算サーバーに送信 |
| 主な用途 | 分散環境でのモデル学習 | 暗号化データの統計処理・マッチング |
| プライバシー保護レベル | 中(推論攻撃リスクあり) | 高(理論的安全性を保証) |
| 計算オーバーヘッド | 低〜中 | 高(暗号化計算のコスト) |
| 通信コスト | 中(パラメータ交換) | 高(暗号文の送受信) |
| 対応する問題 | データサイロ、プライバシー | データ秘匿計算、安全なマッチング |
| 成熟度 | 実用化段階 | 実用化初期段階 |
組み合わせによる相乗効果
連合学習と秘密計算は競合する技術ではなく、相互補完的な技術です。実際のプロジェクトでは、以下のように組み合わせることで、より強固なプライバシー保護を実現できます。
- 連合学習 + 差分プライバシー: 各ノードが送信するパラメータにノイズを加え、個々のデータの影響を数学的に制限
- 連合学習 + 準同型暗号: モデルパラメータを暗号化したまま集約(秘密計算の一手法)
- 連合学習 + セキュアマルチパーティ計算(MPC): 複数ノードが協力して集約処理を行い、中央サーバーへの依存を排除
金融機関における実践では、連合学習でモデルの基本的な学習フローを構築し、秘密計算でパラメータ集約時のプライバシーを強化するという二層構造が効果的です。
> 関連記事: 秘密計算の仕組みや活用事例の詳細は「秘密計算とは?仕組みから活用事例まで徹底解説」をご覧ください。
ユースケース別の使い分けガイド
| ユースケース | 推奨技術 | 理由 |
|---|---|---|
| 複数行での不正検知モデル構築 | 連合学習 + 差分プライバシー | モデル学習が主目的、実用的な精度を確保 |
| 顧客データの安全なマッチング | 秘密計算(PSI) | データ照合が目的、高い秘匿性が必要 |
| クロスセル用の統合スコアリング | 垂直連合学習 + MPC | 異なる特徴量の統合、高い精度と秘匿性 |
| 規制報告のためのデータ集計 | 秘密計算(準同型暗号) | 集計処理が主目的、データ秘匿が最優先 |
連合学習の活用事例
金融業界での活用
不正取引検知
金融業界で最も期待される連合学習のユースケースが、不正取引検知です。個々の金融機関が保有するトランザクションデータには限りがあり、新しい手口の不正取引を検出するには十分なデータ量を確保できないことがあります。
連合学習を活用すれば、複数の金融機関が個々のデータを共有することなく、業界全体のトランザクションパターンから学習した検知モデルを構築できます。欧州の銀行コンソーシアムが実施した実証実験では、連合学習モデルが単一銀行のモデルと比較して不正検知率を約35%向上させたと報告されています。
> 関連記事: 不正検知に使われるAI技術の詳細は「グラフニューラルネットワーク(GNN)とは?」もご参照ください。グラフベースの異常検知と連合学習を組み合わせた手法も研究が進んでいます。
信用スコアリング
複数の金融機関が保有する顧客の取引履歴・返済履歴を連合学習で統合的に学習することで、より精度の高い信用スコアリングモデルを構築できます。特に、クレジットヒストリーが少ない「信用スコアの薄い層」に対する与信判定の精度向上が期待されています。
AML(マネーロンダリング対策)
マネーロンダリングは複数の金融機関をまたいで行われるため、単一機関のデータだけでは全体像の把握が困難です。連合学習により、各金融機関のデータを統合せずに、国際送金の疑わしいパターンを検出するモデルを共同構築する取り組みが進んでいます。
医療・ヘルスケア分野での活用
医療分野は、金融に並ぶ連合学習の有望領域です。患者データは厳格なプライバシー規制(日本では次世代医療基盤法等)の下で管理されており、病院間でのデータ共有は極めて困難です。
連合学習を活用することで、複数の医療機関がCT/MRI画像データを共有せずに、高精度な画像診断AIを共同構築する事例が増えています。特に、希少疾患のように個々の病院では症例数が限られるケースで、連合学習の価値が発揮されます。
GoogleのGboard事例
連合学習の最も有名な実用例は、Googleのスマートフォン向けキーボード「Gboard」です。Gboardは、ユーザーの入力パターンを端末上で学習し、予測変換の精度を向上させています。入力データはGoogleのサーバーに送信されず、学習結果のみが集約されます。
この事例は、数億台のデバイスが参加する大規模な連合学習の実現可能性を示した先駆的なプロジェクトとして、業界に大きなインパクトを与えました。
国内企業の導入事例
日本国内でも、連合学習の実証実験や導入が進んでいます。
- NTTデータ: 金融機関向けの連合学習プラットフォームを開発し、複数行間での不正検知モデルの共同構築を支援
- 富士通: ヘルスケア分野で連合学習を活用した画像診断支援システムを展開
- KDDI: 通信データを活用した連合学習による人流予測の実証実験を実施
金融機関における連合学習の導入ガイド
導入前の検討ポイント
連合学習の導入を検討する際、以下の項目を事前に整理する必要があります。
データ要件
- 各参加者のデータ量は十分か(目安: 各ノード数千件以上)
- データフォーマットは統一されているか
- データの品質管理体制は整備されているか
インフラ要件
- 各拠点間のネットワーク帯域は十分か
- GPU等の計算リソースは各拠点に確保できるか
- 集約サーバーの冗長性・可用性は担保されているか
規制・ガバナンス要件
- 金融庁ガイドラインへの準拠(AI利用に関する内部管理態勢)
- データガバナンス体制の構築
- 参加者間の責任分界の明確化
導入ステップ(PoC→パイロット→本番展開)
フェーズ1: PoC(3〜6ヶ月)
- ユースケースの選定と効果試算
- 小規模データでの技術検証
- 連合学習フレームワークの選定(FLOWER、TFF、PySyft等)
- セキュリティ・プライバシー要件の整理
フェーズ2: パイロット(6〜12ヶ月)
- 2〜3の参加ノードでの実環境テスト
- モデル精度の評価と改善
- 運用プロセスの確立
- 法務・コンプライアンスレビュー
フェーズ3: 本番展開(12ヶ月〜)
- 参加ノードの拡大
- 本番環境でのモニタリング体制構築
- 継続的なモデル改善サイクルの確立
- 新規ユースケースの展開
チーム体制と必要スキル
連合学習プロジェクトでは、通常のAIプロジェクトに加えて、以下の専門スキルが求められます。
- 機械学習エンジニア: 連合学習アルゴリズムの実装・チューニング
- セキュリティエンジニア: 差分プライバシー・暗号化の実装
- インフラエンジニア: 分散環境の構築・運用
- データガバナンス担当: 規制対応・データ管理ポリシーの策定
- プロジェクトマネージャー: 複数組織間の調整
コスト構造と投資対効果
| 項目 | PoCフェーズ | パイロット | 本番運用(年間) |
|---|---|---|---|
| インフラ | 100〜300万円 | 500〜1,500万円 | 1,000〜3,000万円 |
| 開発・人件費 | 300〜800万円 | 1,000〜3,000万円 | 2,000〜5,000万円 |
| ライセンス | 0〜200万円 | 200〜500万円 | 500〜1,500万円 |
| 合計 | 400〜1,300万円 | 1,700〜5,000万円 | 3,500〜9,500万円 |
投資対効果は、ユースケースにより大きく異なります。不正検知の精度向上によるフロード損失の削減額は年間数千万円〜数億円に及ぶケースもあり、ROIは十分に見込めます。
テンファイブでは、金融機関向けのAIソリューション導入支援を行っています。 連合学習の導入検討やPoCの実施について、お気軽にご相談ください。
連合学習の最新動向と今後の展望
大規模言語モデル(LLM)× 連合学習
2025年以降、連合学習の最も注目される応用分野が「LLMの連合ファインチューニング」です。
FedLoRA(Federated Low-Rank Adaptation) は、LoRAのパラメータ効率的なファインチューニング手法と連合学習を組み合わせたアプローチです。各参加者が少量のLoRAパラメータのみを更新・共有するため、通信コストを大幅に削減しながら、組織固有のデータでLLMをカスタマイズできます。
欧米では、複数の金融機関が共同で金融特化LLMを構築するプロジェクトが複数立ち上がっており、日本でも同様の動きが始まりつつあります。
エッジAIとの融合
ATMやPOS端末、スマートフォンなどのエッジデバイスで推論を行いながら、連合学習でモデルを継続的に改善するアーキテクチャが実用化されています。リアルタイム不正検知の精度向上や、パーソナライズされた金融サービスの提供への活用が期待されています。
規制動向と標準化の進展
EU AI Actでは、AIシステムのリスク分類に基づく規制が導入されますが、連合学習のようなプライバシー保護技術の活用は、規制への準拠を容易にする手段として肯定的に位置づけられています。
また、ISO/IECでは連合学習に関する標準化作業が進行中であり、技術仕様の標準化が進むことで、異なる組織・プラットフォーム間での相互運用性が向上すると期待されています。
まとめ
連合学習は、「データを動かさずにAIモデルを構築する」という革新的なアプローチにより、金融業界が直面するデータ活用とプライバシー保護の両立という課題に対する有力な解決策です。
本記事のポイントをまとめます。
- 連合学習は各拠点でローカルに学習し、モデルパラメータのみを共有する分散型機械学習手法
- 3つの手法(水平型・垂直型・転移型)があり、データの分割方法に応じて使い分ける
- 金融業界では不正検知・信用スコアリング・AMLでの活用が進む
- 秘密計算との組み合わせにより、より強固なプライバシー保護が実現可能
- 導入はPoC→パイロット→本番展開の3フェーズで段階的に進める
データ活用の推進とプライバシー保護の両立にお悩みの方は、まず自社のデータ要件とユースケースを整理し、PoCから始めることを推奨します。
テンファイブは、20年以上の金融システム開発実績とAIソリューションの知見を活かし、連合学習の導入支援からAIモデルの構築・運用まで一貫してサポートいたします



