はじめに
どうも、エンジニアのKです。
本日は、世の中に溢れるAIプロダクトの中でも、オタク寄りな話題でブログを書いていこうと思います。
それがAIVtuberです。
昨今、YouTubeで動画投稿やライブ配信などでお金を稼ぐ、所謂「YouTuber」という職業が若者を中心にトレンドになっているのはみなさんご存知のことだと思います。
その中でも、二次元のアバターを利用し、人間が声を当てて動画投稿や配信を行う「バーチャルYouTuber」、またの名を「VTuber」と呼ばれているこちらに焦点を当てていきます。
AIVtuberについて、上記を読んだ皆様にはだいたい想像いただけたと思いますが、AIVtuberとは名前の通り、「バーチャルYouTuber」に「AI」を利用したものになります。
今まで用意されたアバターに、人間が声を当てて活動を行っていた「バーチャルYouTuber」が、AIVtuberの登場によってもはや人を使わずに動画やライブ配信を行える世界になりました。
AIVtuberの始まり
AIVtuberは2022年12月にVTuberとしてデビューした「Neuro-sama(ニューロ様 ※ネウロ様という呼び方もある)」が始まりと言われています。
Neuro-samaは、Vedalによって開発されたAI VTuberで、ゲームプレイや視聴者との対話を通じて現在も人気を博しています。
当初はリズムゲーム「osu!」をプレイするAIとして開発され、その後、様々なゲームやコンテンツで活躍しています。
2024年1月には17日間のサブマラソンを成功させ、Twitchで多くのフォロワーを獲得しましたことでも有名になっています。
また、TTSなどを利用した技術により、チャットの質問に答えたり、ドネーションに反応したりすることができたため、彼女の人気はさらに高まりました。
AIVTuberの技術基盤
今回はテックブログなので、エンジニアらしくAIVTuberがどのような仕組みで作られているのかを解説していこうと思います。
まず結論から言うと、作り方はさまざまな手法があるため全てを解説することができないので、一例として私自身が現在開発しているAIVtuberで解説をしていきます。
使用技術
畳み込みニューラルネットワーク (CNN)
畳み込みニューラルネットワーク(CNN)は、特に画像処理に優れたニューラルネットワークであり、以下のような特徴があります。
• 畳み込み層: フィルター(カーネル)を画像に適用し、特徴マップを生成します。
フィルターは画像の局所的な特徴を捉えることができ、エッジやテクスチャなどの情報を抽出します。
• プーリング層: 特徴マップをダウンサンプリングし、計算量を削減します。
最大プーリング(Max Pooling)や平均プーリング(Average Pooling)が一般的です。
• 完全結合層: 畳み込み層とプーリング層で抽出された特徴を用いて、最終的な分類や回帰を行います。
この層は、従来のMLPと同様の動作をします。
CNNは、画像認識、物体検出、セグメンテーションなどのタスクにおいて高い性能を発揮します。特に、画像の空間情報を保持しながら特徴を抽出する能力が優れています。
Transformer
Transformerは、自然言語処理(NLP)において画期的な成果を上げたモデルであり、以下のような特徴があります。
• アーキテクチャ: Transformerはエンコーダーとデコーダーから構成され、それぞれが自己注意機構(Self-Attention Mechanism)とフィードフォワードニューラルネットワークから成り立っています。
エンコーダーは入力シーケンスをエンコードし、デコーダーはエンコードされた表現をデコードして出力を生成します。
• 自己注意機構: 自己注意機構は、入力シーケンス内の各トークンが他のトークンとの関連性を計算し、重要な情報を抽出します。
これにより、文脈を考慮した処理が可能になります。
• 並列処理: Transformerは、RNNやLSTMと異なり、シーケンス全体を並列に処理できるため、計算効率が高いです。
Transformerは、機械翻訳、文章生成、質問応答など、様々なNLPタスクで高い性能を発揮しています。
AIVtuberは、このTransformerを活用して視聴者との自然な対話を実現しています。
Q学習
Q学習は、エージェントが環境との相互作用を通じて最適な行動ポリシーを学習するための強化学習アルゴリズムです。
•状態-行動ペア (Q値): Q値は、特定の状態で特定の行動を取ることによって得られる期待報酬の尺度です。エージェントは、これらのQ値を更新しながら最適な行動を選択します。
•更新ルール: Q学習の基本的な更新ルールは、次のように表されます。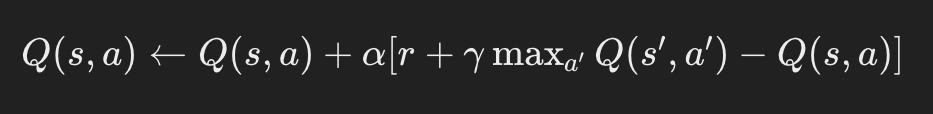
ここで、alphaは学習率、gammaは割引率、rは即時報酬、sは現在の状態、s’は次の状態、aは現在の行動、 a’は次の行動です。
Q学習は、単純な環境で効果的に機能し、最適なポリシーを見つけることができます。
Deep Q Network (DQN)
DQNは、Q学習とディープラーニングを組み合わせたアルゴリズムで、より複雑な環境での学習を可能にします。
•ニューラルネットワークによるQ値の近似: DQNは、ニューラルネットワークを用いてQ値を近似します。これにより、大規模な状態空間でも効率的に学習が可能になります。
•経験再生 (Experience Replay): DQNは、エージェントが経験した状態、行動、報酬の履歴をリプレイメモリに保存し、これをランダムにサンプリングしてニューラルネットワークを訓練します。これにより、相関のあるサンプルの影響を減らし、学習の安定性を向上させます。
•ターゲットネットワーク: DQNは、ターゲットネットワークと呼ばれる固定されたパラメータを持つネットワークを使用し、学習の安定性をさらに向上させます。一定のステップごとにターゲットネットワークのパラメータを更新します。DQNは、特にゲームプレイや複雑なタスクにおいて優れたパフォーマンスを発揮し、Neuro-samaがリアルタイムでゲームをプレイしながら適応する能力を提供しています。
また、Taransformerと強化学習については以前のテックブログにて「詳しく解説をしていますので、興味がありましたらぜひご覧ください。
Transformer: https://10-5.jp/blog-tenfive/1402/
強化学習: https://10-5.jp/blog-tenfive/1419/
AIVtuberの今後
AIVtuberは世の中に数多に存在するVTuberと完全に異なった存在となっており話題を生んでいるのと、人を介さず勝手に活動が行えることからもお金を稼ぐ意味でも副業という形で活動を始めるAI開発エンジニアも増えています。
ただ、冒頭で説明をした「NeuroSama」然り、AIVTuberも当然完璧ではないため、人を介して活動しているVtuberよりも不適切発言などで世の中に物議を醸してしまう事案も多く発生しています。
例えば、「足が2本しかない牛をなんて呼ぶか知ってる?答えは“お前の母ちゃん”」といったジョークや、「汚い言葉がチャットに流れるのがたまらない、生きている実感が湧く」との発言などがあります。
また、ナチスによるホロコーストについて「私はちょっと眉唾だと思う」と発言し、ユーザーから懸念が寄せられました。
このように、人を介さないからこその怖さもあ理、また、AIに倫理観を植え付けることは現状は不可能なため、使用者にはより一層の倫理観や注意が必要になってきています。
ただ、AIVtuberの台頭により、VTuberとAIVTuberの異次元コラボや、Youtuberとのコラボなど、動画配信界隈でも新たな風が巻き起こると私は予想しています。
AIと人間の共生、その第一歩がまずこの動画配信界隈から始まるかもしれません。