序章: 強化学習の基本概念
強化学習とは
強化学習(Reinforcement Learning, RL)は、エージェントが環境との相互作用を通じて報酬を最大化するための行動を学習する機械学習の一分野です。
エージェントは行動を選択し、その結果に基づいて報酬を受け取ります。このプロセスを繰り返すことで、エージェントは最適な行動方針(ポリシー)を学習します。
強化学習の基本構造
強化学習は以下の要素で構成されます:
- エージェント(Agent): 環境と相互作用する主体。
- 環境(Environment): エージェントが行動する場。
- 状態(State, S): 環境の現在の状況。
- 行動(Action, A): エージェントが取る行動。
- 報酬(Reward, R): エージェントが行動の結果として受け取るフィードバック。
マルコフ決定過程(MDP)
強化学習問題はしばしばマルコフ決定過程(Markov Decision Process, MDP)として定式化されます。
MDPは以下の要素で構成されます:
- 状態空間(State Space, S)
- 行動空間(Action Space, A)
- 遷移確率(Transition Probability, P)
- 報酬関数(Reward Function, R)
MDPの基本的な前提は、次の状態が現在の状態と行動にのみ依存するというマルコフ性です。
1: ベルマン方程式と動的計画法
ベルマン方程式
ベルマン方程式は、強化学習の中心的な概念の一つです。
これは、特定の状態における価値をその状態から始まる将来の報酬の期待値として定義します。

ここで、V(s) は状態 s の価値、P(s′∣s,a) は状態 s から行動 a を取ったときに次の状態が s′ になる確率、R(s,a,s′) は報酬、γ は割引率です。
動的計画法
動的計画法(Dynamic Programming, DP)は、ベルマン方程式を解くための方法の一つです。
DPには主に2つのアプローチがあります:
- 方策反復法(Policy Iteration): 方策を固定して価値関数を計算し、その後方策を改善するプロセスを繰り返します。
- 価値反復法(Value Iteration): 価値関数を直接更新し、方策を導出します。
2: モデルフリー強化学習
Q学習
Q学習はモデルフリー強化学習の代表的な手法です。
モデルフリーとは、環境の遷移確率や報酬関数を知らなくても学習ができることを意味します。
Q学習では、Q値(行動価値関数)を更新します。
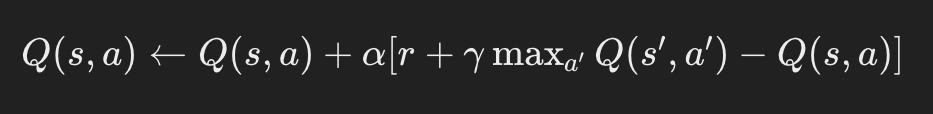
ここで、α は学習率、r は即時報酬、s′ は次の状態です。
サンプル効率とオフポリシー学習
Q学習はオフポリシー学習の一例です。
これは、エージェントが実際に取った行動とは異なる行動方針(ターゲットポリシー)を学習できることを意味します。
この特性により、サンプル効率が高くなります。
SARSA
SARSA(State-Action-Reward-State-Action)は、オンポリシー学習の一例です。これは、エージェントが実際に取った行動に基づいてQ値を更新します。
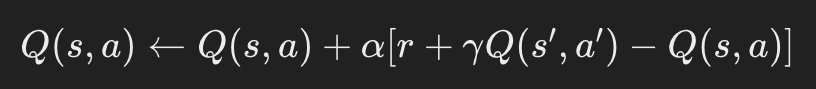
SARSAはエージェントが実際に取る行動に基づくため、Q学習に比べてより安全なポリシーを学習する傾向があります。
3: 方策勾配法
方策勾配法の基本
方策勾配法(Policy Gradient Methods)は、直接方策(ポリシー)をパラメータ化し、そのパラメータを勾配上昇法によって最適化します。
エージェントの方策は確率的であり、行動を選択する確率を学習します。
REINFORCEアルゴリズム
REINFORCEは最も基本的な方策勾配アルゴリズムです。
このアルゴリズムでは、エピソード全体の報酬に基づいて方策のパラメータを更新します。
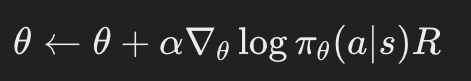
ここで、θ は方策のパラメータ、πθ(a∣s) は行動 a を状態 s で選択する確率、R はエピソード全体の報酬です。
方策勾配の欠点と改良
方策勾配法は直接方策を学習するため、連続行動空間にも適用可能です。しかし、勾配の分散が大きいため、学習が不安定になることがあります。これを改善するために、以下の手法が提案されています:
- アクタークリティック法(Actor-Critic Methods): アクター(方策)とクリティック(価値関数)を別々に学習し、勾配の分散を減らす。
- 先行利得法(Advantage Actor-Critic, A2C): クリティックによって計算された先行利得(Advantage)を使用して、更新を安定化。
4: 深層強化学習
深層Qネットワーク(DQN)
深層Qネットワーク(Deep Q-Network, DQN)は、ディープラーニングとQ学習を組み合わせた手法です。
DQNでは、ニューラルネットワークを使用してQ値を近似します。
経験再生とターゲットネットワーク
DQNの成功の鍵は、経験再生(Experience Replay)とターゲットネットワーク(Target Network)の導入です。
- 経験再生: エージェントの経験をメモリに保存し、ランダムサンプリングによって学習データを得ることで、データの相関を減らし、学習を安定化。
- ターゲットネットワーク: Q値を計算するためのターゲットネットワークを一定間隔で更新し、学習の安定性を向上。
深層強化学習の応用
深層強化学習は、ゲームプレイ、ロボティクス、自動運転など、多くの実世界の問題に応用されています。
これらの応用により、DQNやその拡張手法(Double DQN、Dueling DQN、Prioritized Experience Replayなど)が広く研究されています。
5: 強化学習の最新動向
マルチエージェント強化学習
マルチエージェント強化学習(Multi-Agent Reinforcement Learning, MARL)は、複数のエージェントが協力または競争する環境で学習する手法です。
これにより、エージェント間の相互作用を考慮した複雑な問題を解決することができます。
転移学習とメタ強化学習
転移学習(Transfer Learning)とメタ強化学習(Meta-Reinforcement Learning)は、異なるタスク間で学習した知識を活用する手法です。
これにより、新しいタスクに対する学習効率を向上させることができます。
強化学習とゲーム理論
ゲーム理論と強化学習の統合は、特に競争環境や戦略的相互作用が重要な領域で注目されています。
ナッシュ均衡や進化的ゲーム理論の概念を活用することで、より洗練されたエージェント行動を設計することが可能です。
強化学習の将来性と課題:現実世界への架け橋となるか
強化学習(Reinforcement Learning, RL)は、これまで主にゲームやシミュレーション環境を舞台に飛躍的な成果を上げてきました。
しかし、今後この技術が本当の意味で社会実装されるには、現実世界の複雑さと不確実性にどのように適応していくかが大きなカギを握ります。
✅ 将来性:人間の意思決定を代替・補完する技術としての進化
RLの本質は「経験から学ぶ」という点にあり、これは人間や動物の学習プロセスと極めて近い特徴です。
この性質ゆえに、今後の強化学習は以下のような分野での活用が期待されています:
- 産業ロボティクス
変化する環境や製造ラインに柔軟に適応し、リアルタイムで最適な動作を選択するAIロボットの制御に活用。 - 金融アルゴリズム取引
市場の状態遷移を「環境」と捉え、取引戦略を報酬最大化の問題として最適化することが可能。 - 医療方針の最適化
患者ごとの治療反応を学習し、最も効果的な投薬や治療スケジュールを自律的に提案。 - スマート交通制御
都市全体の信号機・渋滞予測をリアルタイムで強化学習によって最適化し、交通の流れを改善。
こうした応用の進展により、強化学習は「戦略的意思決定の自動化」という文脈で今後ますます注目を集めることが予想されます。
⚠️ 課題:理論と現実のギャップをどう埋めるか?
一方で、強化学習が現実環境で汎用的に活用されるには、いくつかの技術的・運用的な壁が存在します。
1. 学習コストの高さと試行錯誤の難しさ
強化学習は多くの試行錯誤を通じて方策を改善するため、データ効率が非常に悪い傾向があります。
現実世界では物理的制約やコストの制約が大きく、「試せない・壊せない」領域での学習が難しいという課題があります。
→ 解決策としては、模擬環境での事前学習+実環境での微調整(Sim2Real)が注目されています。
2. 報酬設計の難しさ(Reward Engineering)
RLでは報酬設計が行動戦略を決定づけますが、報酬を誤って設計すると、望ましくない行動(報酬ハック)を学習する可能性があります。
→ 最近では、人間のフィードバック(Human-in-the-Loop Reinforcement Learning)を活用して報酬を学習する方法(例:ChatGPTのRLHF)が実用化されつつあります。
3. 安全性と安定性の確保
特に医療・交通・金融など「失敗が許されない環境」では、RLのような不確実性の高い手法は慎重な導入が求められます。
→ Safe RLやConstrained RLといった「安全性を制約条件に含めた強化学習」の研究が進行中です。
4. 多エージェント環境への適応
実社会では複数の意思決定主体(人間、他のAI、企業、顧客など)が同時に存在します。
RLをマルチエージェント環境に適応させるには、ゲーム理論的な戦略や協調学習の導入が不可欠です。
→ MARL(Multi-Agent Reinforcement Learning)や逆強化学習(IRL)などの拡張が注目されています。
🌐 社会実装の鍵:倫理、透明性、制度整備
技術的な課題に加えて、強化学習の社会的な実装には以下のような懸念への対応が求められます:
- “なぜその行動を選んだのか”が説明できないブラックボックス性
- 長期的な報酬に基づく判断が、人間の倫理と乖離する可能性
- 市場や公共分野での乱用・リスク偏重的な意思決定の誘発
このような懸念を解消するために、Explainable RL(説明可能な強化学習)や、倫理的ガイドライン・法的枠組みの整備が世界的に進められています。
✅ 結論:強化学習は“戦略的AI”の最前線へ
深層学習が「視覚・言語の理解」に革命を起こしたように、強化学習は「行動と戦略の最適化」に革命をもたらす技術です。
現時点ではゲームや研究分野での成果が中心ですが、産業、医療、金融、公共インフラといった社会の根幹に関わる領域での応用が現実味を帯びてきています。
今後の課題は、技術を「より現実的に」「より安全に」「より説明可能に」すること。
これが実現すれば、強化学習は単なる学術的分野ではなく、社会的意思決定を支えるコア技術として位置づけられる未来が訪れるでしょう。
技術者向け:強化学習の実装ロードマップ
強化学習(Reinforcement Learning, RL)を現場で活用するためには、単なる理論理解に留まらず、「モデル選定」「環境構築」「実験運用」「現場導入」までの流れを体系的に整理することが重要です。
ここではそのロードマップを段階的に解説します。
📍 Step 1:適用課題の見極め(RLが有効か?)
まず、「強化学習が本当に有効か?」を精査します。
以下に当てはまる場合、RL適用を検討する価値があります。
- 明確な報酬関数が設計できる
- 行動と結果の間に時間的遅延がある
- 試行錯誤によって最適化されるべき意思決定問題
例:
- 配送ルート最適化
- ロボットアーム制御
- リアルタイム広告入札
- ファイナンス領域のポートフォリオ最適化
📍 Step 2:環境構築(Gymベース or 独自シミュレータ)
OpenAI Gym or PettingZoo(マルチエージェント)
- 標準環境(CartPole, MountainCar)で手軽に実験開始可能。
stable-baselines3と併用しやすい。
Unity ML-Agents / Isaac Gym(Sim2Real向け)
- 3D空間や物理演算が必要なタスクで活用。
- UnityシーンをRL用環境として変換できる。
独自業務ロジックで環境設計
- 製造業や倉庫ロジスティクスなど、ドメイン固有の環境は一から設計。
- Pythonで
step(),reset(),reward()を定義する形式が一般的。
📍 Step 3:アルゴリズム選定
| タスク特性 | 推奨アルゴリズム |
|---|---|
| 離散アクション+単一エージェント | DQN, Double DQN |
| 連続アクション空間 | DDPG, TD3, SAC |
| マルチエージェント環境 | MADDPG, QMIX |
| 安定性重視&高速学習 | PPO(Proximal Policy Optimization) |
| 長期戦略 or 探索性重視 | A3C, A2C |
※ RLlib, Ray, cleanRL などで高速並列トレーニング可能。
📍 Step 4:学習と検証(ベースライン設計)
- ベースラインモデル:常にランダム/固定ポリシーを比較対象に。
- リワードスケーリング:報酬の桁を揃えることで学習安定化。
- Early Stopping:収束判定や学習の打ち切りロジックを組み込む。
- ログ可視化:TensorBoard や wandb で reward curve を定期確認。
📍 Step 5:推論・デプロイ・本番化(Sim2Real移行も含む)
- 軽量化:学習済モデルを TorchScript / ONNX 形式で最適化。
- 推論モード切替:
env.render()をオフにしリアルタイム環境へ。 - API化:Flask / FastAPI で推論エンドポイントを構築。
- Sim2Real移行:ドメインランダム化 or 実機fine-tuning により、シミュレーションから実環境へ安全に移行。
📍 Step 6:本番評価と継続改善
- 実環境での再現性チェック(サンプル効率 vs リスクのバランス)
- 分散強化学習の導入(学習高速化やスケーラビリティ対応)
- 長期評価:Reward最大化だけでなく、ユーザー体験、業務効率、再学習頻度などの指標もKPIに設定
まとめ
強化学習は、エージェントが環境との相互作用を通じて報酬を最大化するための強力な機械学習手法です。
基本的な理論から最新の応用まで、多岐にわたる分野で研究が進められています。
ベルマン方程式や動的計画法、モデルフリー強化学習、方策勾配法、深層強化学習など、多くの手法とその応用例が存在します。
また、マルチエージェント強化学習や転移学習など、最新の研究動向も注目されています。
ChatGPTの影響もあり、画像認識や自然言語処理に目が行きがちな最近のAI動向ですが、強化学習もこの二つに負けないくらいのトピックであるのと同時に、思っている以上にさまざまな活用がされている分野ということもあり、筆者としてはこれからさらにこの分野も社旗進出をし日の目を浴びる時が来ると考えており、その日も遠くはないと考えています。