
どうもエンジニアのYです。 最近ChatGPTや、イラスト生成AIモデルであるStable Diffuionなど、さまざまなAIを用いたサービスが展開されています。 そこで今回は、ChatGPTやAmazomのカスタマーサービスなどで使用されているチャットbotなどを作成する技術である、「自然言語処理」について、AI開発未経験者にもわかりやすく解説していきます。

はじめに
皆さんはAI(人工知能)についてどこまで知っていらっしゃるでしょうか。
AI(人工知能)とは、人間の知能をコンピューターや機械で再現する技術で、機械学習や深層学習といったアルゴリズムを使い、大量のデータを解析し、規則やパターンを学習し、新しいデータや未知の状況にも適応できようにし、人間が学習・判断・問題解決を行うようなタスクをコンピューターに行わせることができ、データからパターンを学び、経験から知識を蓄積し、自ら進化することができる名前の通り、人の手で生み出された知能のことです。
まず、AIを生み出す上で大事な手法が2つあります。
1つ目は、機械学習。2つ目は深層学習になります。
どちらも耳にしたことがある方はいらっしゃるかもしれません。
ただ、「二つともどういうものなの?」であったり、「何が違うの?」とお思いになってらっしゃるかと思います。
次のコラムで詳しく解説していきます。
機械学習と深層学習

それでは、このコラムで「機械学習」と「深層学習」の違いについて簡単にまとめていきたいと思います。
・機械学習
機械学習は、データとそれに対応する正解(ラベル)を与えて、コンピュータにデータの特徴やパターンを見つける方法を学ばせる手法です。具体的には、教師あり学習、教師なし学習、強化学習などの種類があります。
・教師あり学習:
データに対する正解が与えられた状態で学習を行います。例えば、写真とその写真に写っているもののラベルを与えて、コンピュータが物体を認識するように学習します。
・教師なし学習:
データに正解が与えられず、コンピュータ自体がデータの構造やクラスタリングを学ぶ手法です。例えば、大量の文章データを与えて、テーマやトピックを自動的に抽出することができます。
・強化学習:
環境と相互作用しながら、報酬を最大化するように学習します。
例えば、ゲームでのAIエージェントは、勝利するために適切な行動を選択することを学習します。
・深層学習
多層のニューラルネットワークを使用してデータから特徴を自動的に学習する手法です。
これは人間の脳の神経細胞を模倣したもので、データを階層的に理解することができます。
深層学習の主要な要素はニューラルネットワークであり、膨大なデータと計算能力を要します。ニューラルネットワークは入力層、中間層(隠れ層)、出力層から構成され、それぞれの層の間には重みと呼ばれるパラメータがあります。データはこのネットワークを通じて伝播し、隠れ層で非線形な特徴を抽出し、最終的に出力層でタスクに応じた予測や分類を行います。
深層学習は、画像認識、音声認識、自然言語処理などのタスクで驚異的な成功を収め、特に大規模なデータセットや高性能なGPUを使うことで、非常に高い精度を達成できます。ただし、データ量が少ない場合や計算リソースが限られている場合は適用が難しいことがあります。
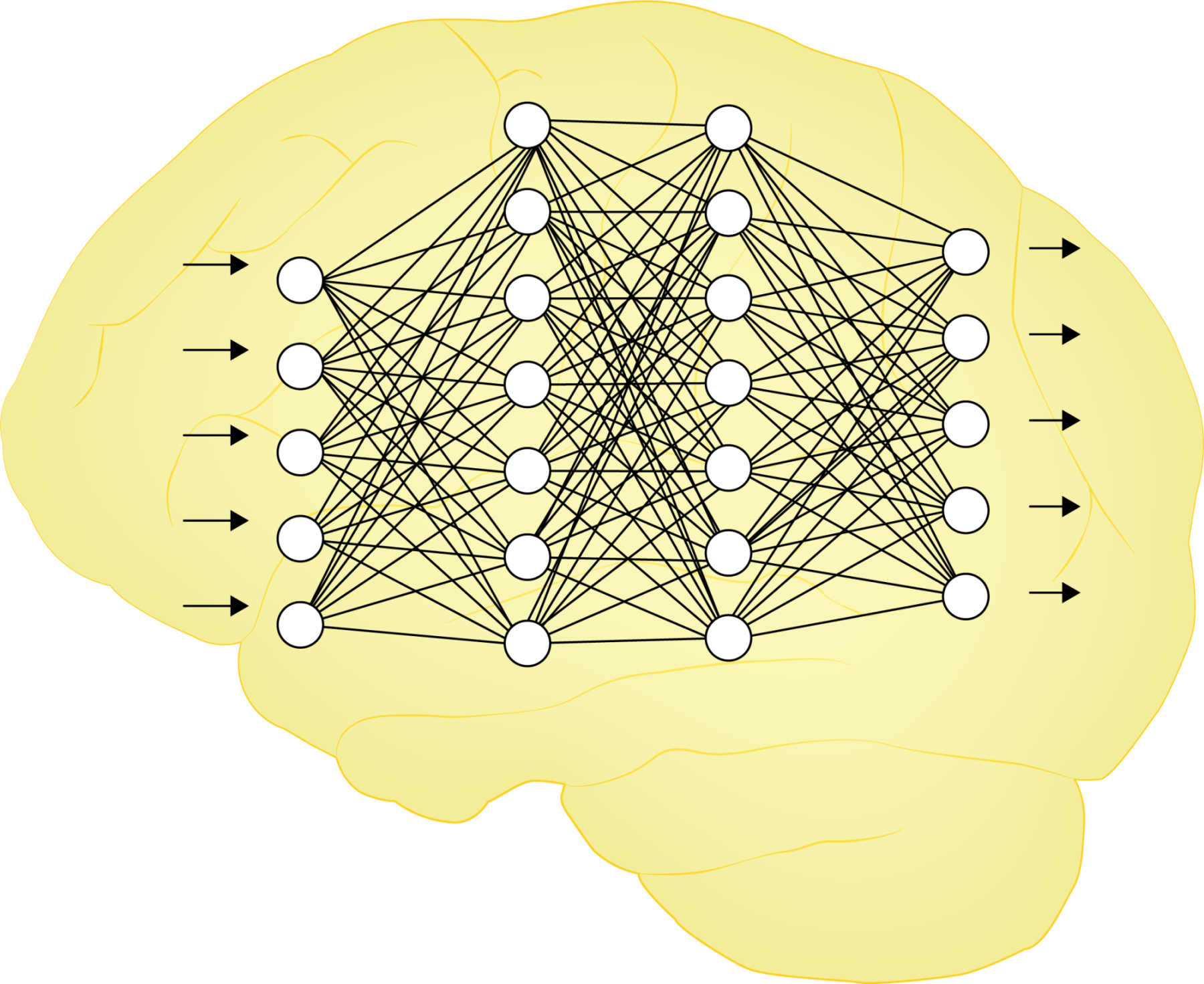
ニューラルネットワークって何?
ニューラルネットワーク(Neural Network)は、人間の脳の神経細胞(ニューロン)の働きを模倣した数学的モデルで、深層学習の基本的な構成要素になります。
脳の神経細胞同士が情報をやり取りするように、ニューラルネットワークは多くの人工的な「ニューロン」がネットワーク状に連結され、データの特徴を学習し、複雑なタスクを解決する能力を持ちます。
ニューラルネットワークは層状の構造を持ち、典型的には、入力層、中間層(隠れ層)、出力層の3つの層がありますが、より深いネットワークは複数の中間層を持ちます。
各層のニューロンは前の層のすべてのニューロンと結合されており、各結合には重みが割り当てられ、ニューロン間の結合パターンと重みが、ネットワークの学習と予測の能力を決定します。
ニューラルネットワークの学習は、教師あり学習の場合、訓練データとそれに対応する正解ラベルを使用します。
学習プロセスでは、入力データをネットワークに入力し、出力と正解ラベルの誤差を測定します。
誤差を最小化するように重みを調整することで、ネットワークは訓練データに適応し、未知のデータに対しても適切な予測を行えるようになるわけです。
深層学習の中でも特に注目されるのは、「畳み込みニューラルネットワーク(CNN)」や「回帰型ニューラルネットワーク(RNN)」です。
CNNは主に画像処理に利用され、画像内の特徴を自動的に学習し、画像認識や物体検出などのタスクにおいて驚異的な成果を上げています。
RNNは主に自然言語処理に利用され、文章生成や文章解析、翻訳などのタスクにおいて、ものすごい成果を上げています。
近年、深層学習とニューラルネットワークの発展により、自然言語処理や音声認識、ゲームプレイなど様々な領域で革新的な応用が増えており、高度なデータ解析とパターン認識の能力により、従来の機械学習アルゴリズムよりも優れた性能を発揮しています。
自然言語処理とは
自然言語処理(Natural Language Processing)は、コンピュータが人間の自然言語を理解し、生成、処理、解析するための技術の分野のことを指します。
自然言語処理では、主に先ほど説明した、機械学習(Machine Learning)、深層学習(Deep Learning)、そして、統計モデルを用いて言語の統計的な性質を学習する統計的手法を用います。
読者の皆さんは上記のような説明を受けても実際どういうタスクがあるのか、まだイメージができないかもしれません。
そこで自然言語処理で行う主なタスクを以下に挙げていきます。
1.言語モデル(Language Modeling):
言語モデルとは、言語の文法や意味を学習して、与えられた文や文脈を理解するためのモデルのことです。
言語モデルは、文の次に来る単語を予測するために訓練され、文章の生成や文脈に基づく処理に用いられます。
Chat-GPTに搭載されているAIモデル「GPT (Generative Pre-trained Transformer)」も、この「言語モデル」と呼ばれるものになります。
2.機械翻訳(Machine Translation):
異なる言語間の文章を自動的に翻訳する技術のことです。
機械翻訳では、対訳コーパス(同じ内容の文が異なる言語で与えられたデータ)を使用してモデルを学習します。
最近では、ニューラル機械翻訳が広く使用され、高い品質の翻訳を実現しています。
身近なものでいうと、Google翻訳やDeepLなどがこの「機械翻訳」と呼ばれるものになります。
3.文書分類(Text Classification):
テキストをカテゴリや感情などのクラスに分類するタスクです。
例えば、スパムメールの判別、感情分析(ポジティブ・ネガティブ判別)などに応用されます。
4.情報抽出(Information Extraction):
テキストから特定の情報(例:人名、場所、日付など)を抽出する技術です。固有表現抽出(Named Entity Recognition)はその一例で、実世界のエンティティを検出するために使用されます。
OCR技術など印刷業界を始め飲食業界などさまざまなところで使用されている技術です。
5.対話システム(Dialogue Systems):
人間と自然な対話を行うAIエージェント(チャットボットなど)の開発が含まれます。対話システムは、ユーザーの要求に適切に応答するために言語理解と生成を組み合わせています。
皆さんが最近使用している「Chat-GPT」や、Amazonなどのカスタマーサービスにあるチャットボットなどもこれになります。
6.文書生成(Text Generation):
文章や要約を自動的に生成する技術です。
文章生成は、音声認識、テキスト要約、文章補完などの応用があります。
Microsoftが開発したMicrosoft Copilotなどはこれに当たります。
Excelなどの関数生成や、資料作成など、人間の事務的タスクに圧倒的な無駄を省くことにもなり、人間の仕事における効率化がますます進むのではないかと私は感じています。
社会実装例

すでに、自然言語処理のコラムでいくつか実装例が上がっていましたが、今回は皆さんにも馴染みが深い「Chat-GPT」に焦点を当てていきたいと思います。
そもそもChat-GPTはOpenAIが開発した、大規模な言語モデルで、GPT(Generative Pre-trained Transformer)シリーズの一部であり、GPT-3.5アーキテクチャに基づいています。
GPTにはいくつかのバージョンがあり、Chat-GPTに搭載されているモデルは、無料版では「GPT-3.5」、有料版では「GPT-4」となっています。
以下に軽く各バージョンについてまとめてみます。
GPT-1:
GPT-1は、2018年にOpenAIによって初めてリリースされた最初のバージョン。
40億のパラメータを持ち、大規模なトランスフォーマーネットワークを使用して言語モデリングを行います。
単語レベルのトークンを入力とし、次の単語を予測するタスクに基づいて事前学習されました。
GPT-2:
GPT-2は、2019年にリリースされた進化したバージョンで、GPT-1よりも大規模で強力なモデル。
GPT-2は1.5億から15億のパラメータを持つ複数のバージョンがあり、より大きなモデルがより高度な表現を行えるようになりました。
その性能は驚くほど良く、文章生成において高い品質を持ち、画期的な成果として広く認識されました。
GPT-3:
GPT-3は、2020年にリリースされたさらなる進化を遂げたバージョンです。
GPT-3は、1750億のパラメータを持ち、これまでのGPTシリーズよりもはるかに大規模であり、より高度なタスクに対応できます。
言語タスクに限定されず、画像の説明生成、プログラミングのサポート、翻訳、文章の要約、質問応答など、さまざまな領域で利用されています。
GPT-3.5:
GPT-3.5は、Chat-GPTに搭載されたさらなる進化を遂げたバージョンです。
GPT-3.5は、3550億のパラメータを持ち、何回かのバージョンアップを通して、現在は「Gpt-3.5-turbo」というモデルがあります。
gpt-3.5-turbo
text-davinci-003の1/10のコストでチャットに最適化されたGPT-3.5最高性能モデルで、翻訳タスクや感情分析タスクなどのにも利用され、従来の4倍の入力に対応し、より中規模データにおいてベクトルデータベースを用いたアーキテクチャより正確で緻密な情報の取得が可能となりました。
GPT-4:
GPT-4は、2023年にリリースされた最新バージョンで、Chat-GPTでは有料会員のみが使用可能となっています。
GPT-4は、1兆7,600億のパラメータを持っていると言われており(正確な値は公式に明かされていない)、GPT-3.5よりもはるかに大規模であり、より高度なタスクに対応できます。
GPT-4には画像自体を解析して分析・要約する高い能力があり、GPT-4に司法試験を解かせたところ、人間の受験者と比べても上位10%の成績を叩き出し、かなりの確率で合格しました。
また、アメリカの大学入試テストとして使われるSATにおいては、1600点中1410点(数学テスト700点、リーディングテスト710点)を獲得しました。
言語タスクに限定されず、画像自体を解析して分析・要約などの要素も加わったため、Microsoftの人工知能開発者は「驚くほど人類の能力に近付いている」と、Chat-GPTの成長に驚いていました。
このようにChat-GPTは日々進化を続けており、現在有料版で使用されている「GPT-4」は人間でいう「視覚」と「言語」を取得しており、どんどん人間に近づいています。
この先は、音声認識機能、人間でいう「聴覚」部分の実装もあるのではないかと私は考えています。
その場合、さらに人間に近づき、全世界にいるAI開発エンジニアの現在の最終目標である「汎用型人工知能」の作成において大きなブレークスルーとなる予感がしています。
ただ、Chat-GPTはすでに世の中の人々がさまざまな用途で使用していると思いますが、何も考えず使用している人が多いと私は感じています。
そこで、私自身が一番大事だと考えていることは、「考えること、疑うことをやめてはいけない」ということです。
というのも、Chat-GPTは強力な手助けになる一方で、非常に大規模な言語モデルのため、どのデータをもとにその出力をしているかがわからない、所謂「ブラックボックス」状態であり、誤解や誤った情報を提供する可能性があるため、注意して使用する必要があります。
さらに、無料版で使用している方は、GPT-3.5を使用されていると思いますが、GPT-3.5の知識は2021年9月までの情報しか対応していない(GPT4も同じく)ので、未来の情報や今現在の情報は把握できていないため、情報が全て過去のものであるという認識が必要であるのと、それをもとに自分でも調査をするということが重要になってきます。
AIが人間を超える「シンギュラリティ」が万が一きてしまった時に、真っ先に犠牲になってしまうのは、何も考えずAIを使用している方々であるのと、今もAIの発達により、存亡の危機に面している職種や業種があるため、そのような高度情報化社会を生き抜いていくためにも、自分で考え、調査をしていく力はこの先さらに必要になってくると思われます。
まとめ
自然言語処理はコロナ禍での画像認識技術の流れから、世間で認知され始め、特に注目に火がついたのは「Chat-GPT」の登場からでした。
まだまだ研究段階で手探りな分野ですが、この先のさらなる進化により、人間とコンピュータの間でよりシームレスなコミュニケーションが実現し、さらに多様な領域での利用が期待されています。
私自身も、先端技術に興味を持っている人間として、AIの行末を見たいと思っています。



