
1. 自然言語処理とは
1-1. 自然言語処理(NLP)の定義
自然言語処理(Natural Language Processing、NLP)は、人間が使用する言語をコンピュータに理解・解析・生成させる技術です。NLPは、言語学、計算機科学、統計学、機械学習などの分野が組み合わさった学際的な領域であり、検索エンジン、チャットボット、翻訳システム、音声認識など幅広い用途に応用されています。
1-2. 自然言語処理の主な応用例
- テキストマイニング(例:ソーシャルメディア分析、感情分析)
- 機械翻訳(例:Google翻訳、DeepL)
- 音声認識(例:Siri、Google Assistant)
- 質問応答システム(例:ChatGPT、Alexa)
- 情報検索(例:検索エンジンのランキングアルゴリズム)
1-3. NLPの発展とトレンド
近年、BERTやGPTなどの大規模言語モデル(LLM: Large Language Models)が登場し、ディープラーニングを活用したNLP技術が飛躍的に進化しました。これにより、従来のルールベースの手法では対応が難しかった高度な言語理解が可能になっています。

2. 形態素解析
2-1. 形態素解析とは
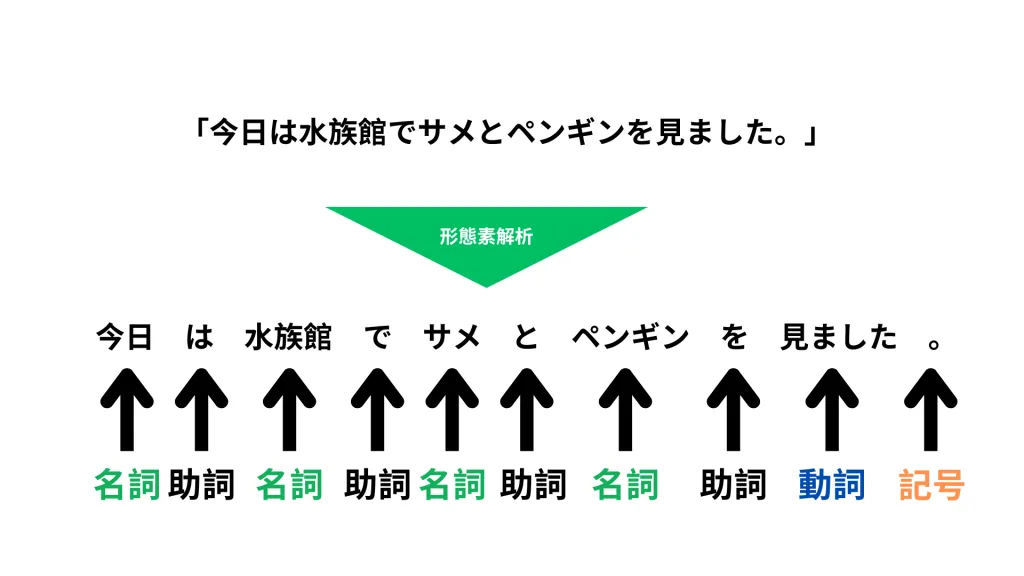
形態素解析(Morphological Analysis)とは、文章を最小単位である「形態素」に分割し、それぞれの品詞や意味を付与するプロセスです。日本語のような形態素の区切りが明確でない言語では、形態素解析が非常に重要な前処理となります。
例えば、以下の文章を形態素解析すると、こうなります。
2-2. 代表的な形態素解析ツール
- MeCab(日本語形態素解析の定番ツール)
- Janome(Pythonで扱いやすい軽量な形態素解析ツール)
- Kuromoji(Java向けの形態素解析ライブラリ)
- Sudachi(最新の形態素解析ツールで、多様な分割方法を提供)
2-3. 形態素解析の課題
- 辞書の精度依存(誤判定が発生する可能性がある)
- 文脈を考慮しにくい(同じ単語でも意味が異なる場合がある)
- 速度と精度のバランス(リアルタイム処理が求められる場合は軽量な解析が必要)
3. 自然言語処理の一般的なフロー
3-1. NLPの処理ステップ
自然言語処理(NLP)は、単に単語を識別するだけではなく、文の構造や意味を理解し、文脈に基づいた処理を行うことが求められます。
そのため、NLPの一般的な処理フローは以下のようなステップに分けられます。
- テキストデータの取得
- 形態素解析(単語分割・品詞タグ付け)
- 構文解析(係り受け関係の分析)
- 意味解析(単語や文の意味の抽出)
- 文脈解析(前後関係や文章全体の意味の理解)
これらのステップを順番に解説していきます。

3-2. 各ステップの詳細
① テキストデータの取得
自然言語処理を行うためには、まず処理対象のテキストデータを収集する必要があります。データのソースには以下のようなものがあります。
- Webスクレイピング(ニュース記事、SNS投稿、ブログなど)
- 公開データセット(Wikipedia、Twitterデータ、ニュースデータなど)
- 企業データ(顧客レビュー、FAQ、チャット履歴など)
適切なデータソースを選び、前処理に進みます。
②構文解析(Syntactic Analysis)
構文解析では、文の構造を解析し、単語間の関係を明らかにします。
具体的には、係り受け関係(どの単語がどの単語にかかるのか)を特定するのが目的です。
例:「私はりんごを食べる。」
- 主語(私は) → 動詞(食べる)
- 目的語(りんごを) → 動詞(食べる)
主な構文解析手法
- 係り受け解析(文法規則に基づいて解析)
- 依存構造解析(依存関係を木構造として解析)
- 句構造解析(文をフレーズ単位で解析)
代表的なツール
- CaboCha(日本語係り受け解析ツール)
- spaCy(英語向けの依存構造解析ライブラリ)
③意味解析(Semantic Analysis)
意味解析では、単語や文の意味を特定します。
形態素解析や構文解析では、文の構造は理解できますが、単語の意味は考慮されません。
意味解析の技術には、以下のようなものがあります。
- 語義曖昧性解消(WSD: Word Sense Disambiguation)
- 例:「銀行に行く」(金融機関) vs 「川の銀行」(河岸の意味)
- 固有表現認識(NER: Named Entity Recognition)
- 例:「東京」は地名、「田中」は人名と認識する
- 単語埋め込み(Word Embedding)
- 例:Word2Vec, FastText, BERT などを使用して単語の意味をベクトル表現化
代表的な手法
- Word2Vec, GloVe(単語の意味を数値ベクトル化)
- BERT, GPT(文脈を考慮した意味理解)
- TF-IDF(単語の重要度を測る)
④文脈解析(Contextual Analysis)
文脈解析では、単語や文の意味を前後の文脈と関連付けて解釈します。
文脈によって単語の意味が変わるため、高度な自然言語処理システムでは必須の技術です。
文脈解析の例
- 「この銀行は金利が高い。」 → 銀行=金融機関
- 「この川の銀行にカモがいる。」 → 銀行=河岸
近年のBERTやGPTなどの大規模言語モデル(LLM)は、この文脈解析を高精度に行うことができます。
主な手法
- リカレントニューラルネットワーク(RNN, LSTM, GRU)
- トランスフォーマー(Transformer: BERT, GPT)
4. 自然言語処理のためのデータの前処理
NLPの精度を左右する重要なステップが「データの前処理」です。
データの質が低いと、どんな高度なアルゴリズムを使っても良い結果は得られません。
4-1. 主要な前処理手法
① トークン化(Tokenization)
テキストを単語や文に分割する処理。日本語の場合は形態素解析が必要。
② 正規化(Normalization)
異なる表記の統一(例:「ABC」→「ABC」、「㈱」→「株式会社」)。
③ ストップワード除去
意味を持たない単語(「の」「は」「に」など)を削除。
④ ステミングとレンマ化
単語の語幹を統一(例:「走る」「走った」→「走る」)。
⑤ ベクトル化
単語を数値として扱うための変換(TF-IDF、Word2Vec、BERT埋め込みなど)。
5. まとめ
本カリキュラムでは、自然言語処理(NLP)の基礎から応用までを体系的に学びました。
特に、形態素解析の重要性、自然言語処理のワークフロー、そしてデータの前処理の具体的な手法について解説しました。
近年のNLPの発展は著しく、大規模言語モデル(LLM)を活用することで、より高度な自然言語処理が可能になっています。
今後は、BERTやGPTのような技術を活かした実践的なプロジェクトに挑戦し、NLPのスキルを磨いていきましょう!

