
1. はじめに
近年、深層強化学習(Deep Reinforcement Learning, DRL) は、自動運転やゲームAI、ロボティクスなど多岐にわたる分野で革新をもたらしています。強化学習とは、エージェント(AI)が試行錯誤を通じて最適な行動を学習する枠組みです。特に、ディープラーニングと組み合わせることで、より複雑なタスクを処理できるようになりました。
本記事では、強化学習の基本原理から、主要な学習理論、深層強化学習の登場までを体系的に解説します。数式や理論も扱いますが、初心者でも理解しやすいように丁寧に説明します。

2. 強化学習の基本原理
2.1 強化学習とは?
強化学習は、エージェント(学習者)が環境(Environment) と相互作用しながら、試行錯誤を通じて最適な行動戦略(ポリシー)を学ぶ機械学習の一種です。
強化学習の基本構造
強化学習の枠組みは、以下の要素で構成されます:
- エージェント(Agent):学習する主体(AIやロボットなど)
- 環境(Environment):エージェントが行動する場(ゲーム、現実世界など)
- 状態(State, S):環境の現在の情報
- 行動(Action, A):エージェントが選択できる行動
- 報酬(Reward, R):行動の良し悪しを評価する指標
- 方策(Policy, π):エージェントがどの状態でどの行動をとるかを決定するルール
エージェントは、最大の累積報酬を得るように行動を最適化 します。
3. 強化学習の学習法の理論
強化学習では、エージェントが長期的に最適な行動を選択できるように、様々な学習手法が用いられます。
3.1 割引率(Discount Factor, γ)
強化学習では、現在の行動だけでなく、将来得られる報酬も考慮します。しかし、遠い未来の報酬は現在の報酬よりも価値が低い ことが一般的です。そのため、報酬には「割引率(γ)」を掛けて調整します。
割引報酬の計算式:
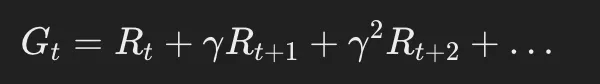
ここで、
- 0≤γ≤10
- γが1に近いと、遠い未来の報酬も重視
- γが0に近いと、短期的な報酬を優先
3.2 価値関数(Value Function)
エージェントがどの状態でどの程度の報酬が期待できるかを数値化する関数です。
- 状態価値関数(V関数):ある状態 Sから得られる累積報酬の期待値
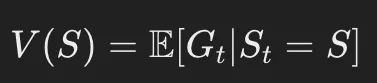
・状態価値関数(V関数):ある状態 Sから得られる累積報酬の期待値

3.3 方策勾配法(Policy Gradient)
強化学習の方策(ポリシー)を直接学習する手法で、ニューラルネットワークを利用することが多いです。
- 確率的方策 を用いることで、柔軟な行動選択が可能
- 勾配上昇法を用いて、方策のパラメータを更新
- 代表的なアルゴリズム:REINFORCE、PPO(Proximal Policy Optimization)
3.4 バンディットアルゴリズム
「探索と活用のトレードオフ」を扱う問題の解決手法。特に、未知の環境でどの選択肢が最も報酬が高いかを学習する際に用いられます。
- ε-greedy法:ランダムに探索(εの確率)しつつ、最良の選択肢を活用
- UCB(Upper Confidence Bound):不確実性を考慮して、最も有望な選択肢を優先
3.5 マルコフ決定過程(MDP, Markov Decision Process)
強化学習の理論的基盤となるモデル。
- 現在の状態だけが次の状態に影響を与える(マルコフ性)
- MDPは (S, A, P, R, γ) で定義される
- S:状態
- A:行動
- P:状態遷移確率
- R:報酬関数
- γ:割引率
4. 深層強化学習の登場
ディープラーニングを活用することで、強化学習はより高度な問題に適用可能になりました。
4.1 深層強化学習(Deep Reinforcement Learning, DRL)とは?
ニューラルネットワークを用いて価値関数や方策を近似する手法 です。代表的なアルゴリズムとして、以下があります。
- DQN(Deep Q-Network):ディープラーニングを活用したQ学習
- A3C(Asynchronous Advantage Actor-Critic):方策勾配法+価値関数を組み合わせた手法
- PPO(Proximal Policy Optimization):安定した学習が可能な方策勾配法
4.2 深層強化学習の応用分野
- ゲームAI(AlphaGo、OpenAI Five)
- 自動運転(WaymoのAI)
- ロボティクス(ロボットの運動制御)
5. まとめ
本記事では、強化学習の基本から、主要な学習理論、そして深層強化学習までを解説しました。
ディープラーニングの発展により、強化学習はさらに進化を続けています。


