
データサイエンスのスキルを本気で鍛えたいなら、教科書や講座だけではなく、実際にデータに触れて、実践的なプロジェクトに挑むことが重要です。
そこで、世界中のデータサイエンティストたちが競い合う場「Kaggle」が注目されています。
初心者からエキスパートまで、多様なレベルの参加者が集まり、リアルなデータセットを使って問題を解決する場であり、業界での実績作りにもつながります。
筆者もKaggleに参加しており、現在は上から3つ目のKaglgle Expertに属しています。
この記事では、Kaggleの魅力と使い方、そして成功するためのポイントを詳しく紹介します。

1.Kaggleとは何か?
Kaggleは、2010年に設立され、現在はGoogleの一部として運営されている、データサイエンスと機械学習に特化した競技プラットフォームです。
Kaggleでは、ユーザーはさまざまな公開データセットを利用して、機械学習モデルを構築し、その予測精度や解決力を競い合います。
プラットフォームは、学術的な研究者や企業、個人開発者が、現実世界の問題をデータを使って解決するための場を提供します。
Kaggleには主に次の3つの特徴があります:
1. コンペティション
Kaggleの中心となる機能が「コンペティション」です。
Kaggleでは、さまざまな企業や研究機関が現実世界のデータセットを提供し、それをもとに参加者が競技を行います。
課題には、例えば画像認識、自然言語処理、推薦システムの構築などがあり、これらの問題に対して参加者は最も効果的な機械学習モデルを提出します。
コンペティションはランキング形式で行われ、上位に入賞すると賞金が提供されることもあります。
コンペティションは初心者向けから上級者向けまでさまざまな難易度があり、自分のレベルに応じて参加することが可能です。
これにより、初学者は実践的な学習を行いながら、徐々にスキルを伸ばすことができます。
2. カーネル(Kaggle Notebooks)
カーネル(現在はKaggle Notebooksとして知られています)は、ユーザーがPythonやRを使って直接プラットフォーム上でデータを処理し、モデルを構築できる環境を提供します。
これにより、ユーザーは自身のコードを共有したり、他のユーザーのコードを参照して学習することができます。
カーネルはデータの前処理、可視化、機械学習モデルのトレーニング、評価など、データサイエンスのフルワークフローをカバーしています。
他のユーザーのカーネルをフォークして自分なりに改良したり、既存の優れた解決策を研究することで、効率的にスキルを伸ばすことができます。
3. データセット
Kaggleは、膨大な数のデータセットを公開しています。
これには、学術的なプロジェクトやビジネス向けのデータ、さらにはオープンな公共データセットまで含まれています。
たとえば、アメリカ合衆国国勢調査局のデータ、IMDbの映画データベース、アマゾンのレビューなどが利用可能です。
ユーザーは、これらのデータセットを自由に利用して自分のプロジェクトを進めることができ、データセットの特徴や欠損値処理、前処理など、データサイエンスにおける重要なスキルを実践的に学ぶことができます。
さらに、ユーザー自身も独自のデータセットをアップロードし、他の人と共有することができます。
Kaggleは、学習から競技、そして実践まで、データサイエンスをあらゆる角度から学ぶための包括的なプラットフォームです。
データサイエンティストとしてのキャリアを目指す人にとって、貴重なリソースであり、実績を積む場でもあります。
2. Kaggleのランク制度について
Kaggleでは、参加者がコンペティションやノートブック(カーネル)での貢献度に応じて、実績を評価するためのランク制度が設けられています。
このランク制度は、参加者のスキルや経験を視覚的に示す指標であり、他のユーザーとの比較がしやすく、データサイエンス業界でも評価される要素の一つです。
Kaggleで上位のランクを得ることは、業界での知名度を高め、キャリアにおいても有利なものとなります。
1. ランク制度の概要
Kaggleでは、4つのメインカテゴリでランクが評価されます:
- コンペティション
- データセット
- ノートブック(カーネル)
- ディスカッション
各カテゴリごとに、ユーザーは貢献や結果に基づいてポイントを取得し、それに応じたランクが与えられます。
ランクは次のように区分されています:
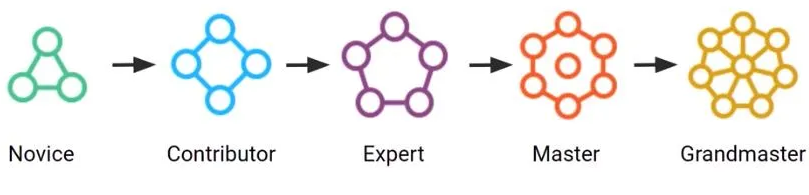
- Novice(ノービス)
初心者向けのランクです。
Kaggleに新規登録した際や、まだコンペティションやノートブックの活動実績が少ないユーザーが対象となります。
最初の数回の参加で少しずつランクを上げることが目標です。 - Contributor(コントリビューター)
ある程度の貢献が認められると、このランクに昇格します。
Kaggle上での活動、特にコンペティションやノートブックでの結果や他のユーザーへの貢献によって、このランクに到達します。 - Expert(エキスパート)
高いスキルを持ち、Kaggleで一定の成功を収めたユーザーに与えられます。
コンペティションで上位の結果を残したり、データセットやノートブックで優れた成果を発表したユーザーが対象です。このランクから、業界内での評価も上がりやすくなります。 - Master(マスター)
多くのKaggleユーザーが目指す目標の一つです。
マスターランクを達成するには、複数のコンペティションで高評価を得たり、特に貴重なデータセットやノートブックを提供して、他のユーザーからの高い評価を得ることが必要です。
マスターランクに到達すると、データサイエンスコミュニティ内での評価は非常に高くなります。
また、日本ではマスター称号保持者はわずか200人ほどしかいないとされています。 - Grandmaster(グランドマスター)
Kaggleにおける最高位で、非常に限られた数のユーザーのみが到達できるランクです。
長期間にわたる卓越したパフォーマンスや、多くのコンペティションでの優勝など、トップレベルの貢献が求められます。
グランドマスターは、データサイエンス業界でのキャリアにおいても極めて強力な実績となります。
2. ランクを上げるための方法
Kaggleのランクは、以下の要素に基づいて評価されます:
• コンペティションでの結果
Kaggleの主要な評価基準は、コンペティションでのパフォーマンスです。
高精度の機械学習モデルを構築し、他の参加者とスコアを競い合うことでポイントが与えられます。
特に、コンペティション終了時の順位が高ければ高いほど、より多くのポイントを獲得できます。
• ノートブックの貢献
優れたノートブック(カーネル)を作成し、他のユーザーにとって役立つ内容を提供することも評価されます。
ノートブックは、データの前処理や可視化、モデルの構築に関するコードと結果を共有できる場所です。
多くのユーザーから高評価を受けるノートブックを公開することで、ポイントを獲得できます。
• データセットの提供
Kaggleにはユーザーが独自にデータセットをアップロードできる機能があり、他のユーザーがそのデータセットを利用すると評価ポイントを獲得できます。
特に、珍しいデータセットや、使いやすい形に整備されたデータが高く評価されやすいです。
• ディスカッションへの貢献
フォーラムやディスカッションでの積極的な発言や他のユーザーへのサポートも、Kaggleのランクアップに繋がります。
質問に答えたり、技術的なアドバイスを提供することで、コミュニティ内での評価が高まり、ポイントを得ることができます。
3. Kaggleランクの意義
Kaggleで高いランクを達成することは、データサイエンスのスキルを客観的に示すための重要な指標となります。
特に、企業がデータサイエンティストを採用する際に、Kaggleでの実績を重視することが増えてきています。
ランクが高いユーザーは、実際のデータ分析プロジェクトでの成功経験が豊富であると見なされ、キャリアの上でも有利に働くことが多いです。
さらに、Kaggleのグランドマスターはコミュニティ内でのリーダー的存在となり、新たなプロジェクトやコンペティションの指導者としての役割を果たすこともあります。
KaggleでMaster称号を獲得すると、国内はもちろん海外の大手Tech企業でのAIプロジェクトにも参画することができます。
現に、GoogleやMicrosoft,MetaやAppleなどはKaggleでの上位称号保持者を積極的に採用しています。
3. Kaggleの使い方
Kaggleはデータサイエンスや機械学習を学ぶための強力なツールですが、初めて利用する人にとっては、どこから始めたらよいか迷ってしまうこともあります。
ここでは、Kaggleを効果的に使い始めるためのステップを詳しく解説します。
1. アカウントを作成する
Kaggleを利用するには、まずアカウントを作成する必要があります。
Kaggleの公式サイト(https://www.kaggle.com/)にアクセスし、右上の「Sign Up」ボタンから登録を開始します。
• Googleアカウントでの登録が簡単
KaggleはGoogleが運営しているため、Googleアカウントを使って簡単にサインアップが可能です。
これにより、ログイン時にパスワードを管理する手間が省け、すぐに活動を開始できます。
もちろん、FacebookやGitHubアカウントでも登録できますが、Googleアカウントが最も一般的です。
• プロフィールを設定する
アカウントを作成した後、プロフィールを充実させておくと他のユーザーからの信頼感が向上します。
自己紹介や専門分野、興味のある技術について簡単に記載することで、将来的にチームコンペティションへの参加やネットワーキングに役立ちます。
2. データセットを探す
Kaggleの魅力の一つは、豊富なデータセットを自由に活用できる点です。
データセットは、ビジネス、健康、金融、スポーツなどさまざまな業界やトピックにわたります。
• データページにアクセス
データセットは、Kaggleのトップページにある「Datasets」セクションから簡単に探せます。
ここでは、フィルターやキーワード検索を使って、目的に合ったデータセットを探すことができます。
• データセットの選び方
初心者の場合、最初に取り組むデータセットとしては、比較的シンプルなものを選ぶと良いでしょう。
たとえば、Kaggleが提供している「Titanic: Machine Learning from Disaster」や「House Prices: Advanced Regression Techniques」といった初心者向けのコンペティションのデータセットは、よく構造化されており、データ前処理やモデル構築の練習に最適です。
• データの前処理からスタート
データセットをダウンロードしたら、まずはデータの内容を確認し、欠損値や異常値を処理することから始めましょう。
データサイエンスの多くの作業は前処理にかかっているため、このステップが重要です。
Kaggleには他のユーザーが公開した「Notebooks」(カーネル)もあるので、どのようにデータを前処理しているかを参考にできます。
3. コンペティションに参加する
Kaggleのコンペティションは、実際のデータを使って機械学習モデルを作成し、他の参加者とスコアを競うイベントです。
コンペティションは常時開催されており、初心者向けからプロフェッショナル向けまで、難易度やテーマが幅広く用意されています。
• コンペティションに挑戦するステップ
Kaggleの「Competitions」ページから、興味のあるコンペティションを選びましょう。
コンペティションの概要、課題、提出形式、評価方法などが詳しく説明されています。
参加者はこれらの情報をもとに、最適なモデルを開発して予測を行い、スコアを競います。
• 評価メトリクスの理解
コンペティションごとに、評価の基準となるメトリクス(例えば、精度、F1スコア、ROC AUCなど)が設定されています。
これらのメトリクスを理解し、モデルの改善に役立てることが、コンペティションで成功するための鍵です。
• 最初はチュートリアルに挑戦
初心者の場合、「Titanic: Machine Learning from Disaster」など、入門者向けのチュートリアルコンペティションがおすすめです。
ここでは、基本的なデータ処理やモデルの構築がステップバイステップで説明されており、初めてのKaggle体験には最適です。
4. カーネルでコードをシェアする
Kaggleの「カーネル」(現在は「Notebooks」と呼ばれています)は、Kaggleユーザーがコードやデータ分析プロセスを共有するためのツールです。
この機能を使えば、オンライン上でコードを書き、他のユーザーと共有し、フィードバックを受けることができます。
Jupyter Notebook形式での編集が可能なため、手軽にデータの可視化やモデルの作成を行えます。
• 他のユーザーのカーネルを参照する
Kaggleでは、コンペティションやデータセットごとに、他の参加者が作成したカーネルを見ることができます。
特に上位入賞者のカーネルを参考にすることで、どのようなアプローチが有効だったのかを学び、スキル向上に役立てることができます。
• 自分のカーネルを公開する
カーネルは、他のユーザーにフィードバックを求めたり、同じデータに対して異なるアプローチを試したい場合に便利です。
自分で分析したデータや構築したモデルを公開し、他のユーザーからのコメントを得ることで、学びを深めることができます。
また、カーネルが多くの「Upvote」(いいね)を得ると、Kaggleの評価ポイントが加算され、ランクアップに貢献します。
• カーネルのフォーク機能
他のユーザーが作成したカーネルを「フォーク」して、自分のバージョンとしてカスタマイズすることも可能です。
これにより、既存の分析プロセスをベースに、自分の工夫を加えて新たな解決策を探ることができます。
4. Kaggleで成功するためのヒント
Kaggleで上位に食い込むためには、単に機械学習モデルを構築するだけでなく、データの扱い方や他の参加者との協力など、いくつかの重要な要素を意識する必要があります。
ここでは、Kaggleで成果を上げるための具体的な戦略を解説します。
1. データの前処理に時間をかける
機械学習モデルの精度は、元のデータの質に大きく左右されます。
そのため、コンペティションで成功するための最初のステップは、データの前処理に十分な時間を割くことです。
以下は、前処理で特に重要なポイントです。
- 欠損値の処理
多くの実世界のデータセットでは、欠損値が含まれています。
欠損値を無視すると、モデルの精度が低下するため、適切な方法で欠損値を補完することが重要です。
例えば、平均値や中央値で埋める、もしくはk近傍法(KNN)などの手法を使って、より精度の高い欠損値補完を行います。 - データの正規化とスケーリング
数値データが異なるスケールである場合、機械学習アルゴリズムが正確に学習できないことがあります。
そのため、特徴量を正規化(例えば0〜1の範囲に収める)や標準化(平均0、標準偏差1に変換)することで、アルゴリズムが効率的に学習できるようにすることが重要です。 - 外れ値の処理
外れ値(通常の範囲から大きく逸脱したデータ)は、モデルの学習に悪影響を及ぼすことがあります。
外れ値を特定し、除去するか、別の形で処理することも前処理の一環です。
例えば、ボックスプロットを使って外れ値を検出したり、ロバストスケーリング手法を適用することで、外れ値の影響を緩和できます。 - 特徴量エンジニアリング
単に与えられたデータをそのまま使うのではなく、新しい特徴量を作り出すことで、モデルのパフォーマンスが大幅に向上することがあります。
例えば、日時データから「月」「曜日」「時間」などの特徴を抽出したり、複数の特徴量を組み合わせて新しい指標を作成することも可能です。
これを「特徴量エンジニアリング」と呼び、競争力を高める重要なスキルです。
2. 他の参加者のソリューションを学ぶ
Kaggleの大きな利点の一つは、他の参加者のソリューションを学べることです。
トップ参加者が提出するノートブック(カーネル)は、最先端の技術や戦略が詰まっており、それを学ぶことで自分のスキルを向上させることができます。
• ソリューションの読み解き方
コンペティションが終了した後、多くの上位参加者が自分のソリューションを公開します。
これらのソリューションは、データ前処理やモデル選択、ハイパーパラメータチューニングの方法など、非常に参考になる部分が多いです。
どのようにして高いスコアを達成したのかを詳細に読み解き、自分の分析に取り入れることが重要です。
• 新しい技術を学ぶ
トップ参加者のノートブックには、最新のアルゴリズムや最適化手法が使用されていることが多いです。
たとえば、LightGBMやXGBoostといった人気のあるモデルだけでなく、アンサンブル学習やスタッキングなど、モデルを組み合わせて性能を向上させるテクニックがよく使われます。
これらの技術を学び、実際に試してみることで、自分のスキルがさらに向上します。
• コードをフォークして実践する
他の参加者のノートブックを「フォーク」して、自分なりに改良したり、別のアプローチを試してみることも良い学びになります。
Kaggleでは、フォーク機能を使って簡単に他のソリューションを自分の環境で試すことができるため、実際に手を動かして学ぶことが大切です。
3. チームでの参加を検討する
Kaggleの多くのコンペティションでは、チームでの参加が可能です。
個人で挑戦することもできますが、チームで取り組むことで、より優れた結果を得られる場合が多いです。
• 異なるスキルセットを組み合わせる
チームで参加することで、異なるスキルセットや視点を持つメンバーが協力し、より強力なモデルを作り上げることができます。
例えば、データ前処理が得意なメンバー、モデル構築に長けたメンバー、ハイパーパラメータのチューニングが上手なメンバーが協力することで、個人では思いつかないようなアプローチを試すことが可能です。
• 役割分担による効率化
コンペティションでは限られた時間の中で最適なモデルを作成する必要があります。
チームで参加することで、作業を役割分担し、効率的に進めることができます。
例えば、あるメンバーがデータのクレンジングに集中し、別のメンバーが特徴量エンジニアリングを行い、他のメンバーがモデルのチューニングを行うといった分業が可能です。
• フィードバックを通じて成長する
チーム内でのディスカッションやフィードバックを通じて、自分の弱点や改善点に気づくことができます。
異なる視点からのアプローチを学ぶことも、将来のコンペティションでの成功に繋がります。
チームでの成功体験は、自分のモチベーションを高めるだけでなく、他のメンバーと共に成長する大きなチャンスとなります。
まとめ
Kaggleは、データサイエンスやAI開発のスキルを実践的に高めるための最適なプラットフォームです。
単なるコンテストの場にとどまらず、データセットの宝庫であり、学習コミュニティとしても機能しています。
初心者でも気軽に始められる一方で、上級者にとっても新たなチャレンジを提供してくれる場です。
これからデータサイエンスやAI開発の世界で活躍したい方は、Kaggleで自分のスキルを試し、競争力を磨きましょう!

