
現代社会において、人工知能(AI)は私たちの日常生活やビジネスにおいて欠かせない存在となっています。AIは、検索エンジンや音声アシスタント、画像認識技術など、さまざまな場面で活躍し、私たちの生活をより便利に、そして効率的にしています。
この講座に辿り着いた皆さんも、AIに大なり小なり興味がある方々であると存じます。
では、「人工知能」とは一体何なのでしょうか? AIは単なる技術の一部に過ぎないと思われがちですが、その本質は、機械が人間の知的な行動を模倣する能力にあります。
このコースでは、AIの勉強を進めていく上で基本的な知識を教えていきます。
AIの基礎をしっかりと理解し、この講座を最後までやり切ることで、将来的にAI開発エンジニアとしての一歩を踏み出すことができるようになりますので頑張っていきましょう。
1.人工知能(AI)の定義
私たちは、日常的に「人工知能」「機械学習」「ディープラーニング」などの言葉に触れるようになりました。
しかしながら、皆さんはこれらの用語の正しい定義を自分の言葉で説明できるでしょうか?
例えば、次の2つの質問についてじっくり考えてみてください。
- 「人工知能とは?」
- 「人工知能と機械学習はどう違うの?」
各概念の本質を正しく理解することで、ここからの学習もスムーズに進めていくことができます。
1.1 AIとは
「AI」は「Artificial Intelligence(アーティフィシャル・インテリジェンス)」の略で、日本語では「人工知能」と訳されます。
この名称には、それぞれ重要な意味が含まれています:
• Artificial(人工)
「人工」は「人間が作り出したもの」という意味です。AIは、人間の手で設計され、プログラムされたシステムやアルゴリズムを指します。
つまり、自然に存在するものではなく、技術者や研究者が開発した知能です。
• Intelligence(知能)
「知能」は「学習し、理解し、推論し、問題を解決する能力」を指します。
これは人間や動物が持つ知的な働きと同様のもので、AIはそれを模倣することを目指しています。
したがって、「Artificial Intelligence(人工知能)」とは、人間が設計・開発したものであり、知的な作業を模倣し、学習・推論・判断などを行う技術やシステムを意味します。
ただ、実は、AIには「絶対的な定義」は定められておらず、その定義に関しては専門家の中でも意見が異なります。
例えば以下に、人工知能学会誌に掲載されている専門家の定義を挙げます。
| 発表者 | 定義 |
| 松尾豊(東京大学大学院工学系研究科教授) | 人工的に作られた人間のような知能、ないしはそれを作る技術 |
| 松原仁(東京大学次世代知能科学研究センター教授) | 究極的には人間と区別ができない人工的な知能 |
| 武田英明(国立情報学研究所教授) | 人工的に作られた知能を持つ実態。あるいはそれを作ろうとすることによって知能自体を研究する分野 |
| 長尾真(京都大学名誉教授) | 人間の頭脳活動を極限までシミュレートするシステム |
上記のように、専門家でも定義は定まっておらず各々が自由な意見を持っていることがわかります。
なぜなのか、その理由は簡単で、そもそも人間に備わっている「知能」や「知性」そのものの意味が一つにまとめることができないからです。
だからこそ、近年多くのAI(人工知能)が搭載されたプロダクトが出回っていますが、そのプロダクトを「AI」とみなせるか否かは人によって食い違っているのです。
1.2 人工知能の歴史
人工知能(AI)の歴史は、1950年代にまでさかのぼります。
中でも重要な出来事として挙げられるのが、1956年に開催されたダートマス会議です。
この会議で、ジョン・マッカーシー(John McCarthy)が「人工知能(Artificial Intelligence)」という言葉を初めて提案しました。
ジョン・マッカーシーは、AI分野の先駆者として知られており、彼はコンピュータが知的行動を模倣できるという概念を掲げました。
ダートマス会議は、このアイデアに基づいて、当時のコンピュータ科学者や数学者が集まり、「機械が人間のように考えることができるか」というテーマを討論する場となりました。
この会議には、マーヴィン・ミンスキーやクラウド・シャノンなど、AI分野の他の重要な人物も参加していました。
ダートマス会議がAIの歴史において特に重要なのは、ここで人工知能が正式に「研究分野」として認められたことです。
会議の成果として、AIは単なるコンピュータプログラムの延長ではなく、人間の知能を模倣する新しい科学的領域であると考えられるようになりました。
このように、1956年のダートマス会議がきっかけで、人工知能は学問分野としてスタートし、現在に至るまでその発展を続けています。
2.人工知能と機械学習
人工知能(AI)は、コンピュータに人間の知的な作業を模倣させる技術ですが、その中でも特に重要な技術として機械学習(Machine Learning)が挙げられます。
機械学習は、AIが単なるプログラムされた動作を超えて、自らデータを学習し、経験から成長する能力を提供する仕組みです。
従来のプログラムでは、すべての動作が人間によってあらかじめ決められていましたが、機械学習を用いることで、AIは与えられたデータからパターンを見つけ、未知のデータに対しても適切な判断を行うことが可能になります。
たとえば、顔認識技術や自動運転車、推薦システムなど、私たちの日常生活で使われている多くのAIは、この機械学習の技術に支えられています。
「AI=機械学習」と世間の皆様は思いがちですが、実際は「機械学習」は「AI」を実現するための一つの手段にすぎません。
ここでは、人工知能と機械学習の関係性について学んでいきます。
2.1 人工知能と機械学習の関係性
最初に「機械学習 (Machine Learning)」を定義づけたのは、学習型プログラムをはじめて開発した米国の計算機科学者のアーサー・サミュエル (Arthur Samuel) です。
この定義は以下のとおりです。
「明示的にプログラムしなくても学習する能力をコンピューターに与える研究分野」
先の「人工知能と機械学習はどのような関係にあるか」に対するイメージを下記に示しました。
下記に示すとおり、機械学習とは人工知能の中の1つの手法で、人工知能は、大きくルールベースと機械学習の2つの手法に分けることができます。
言い換えると、機械学習は人工知能の部分集合にあたります。
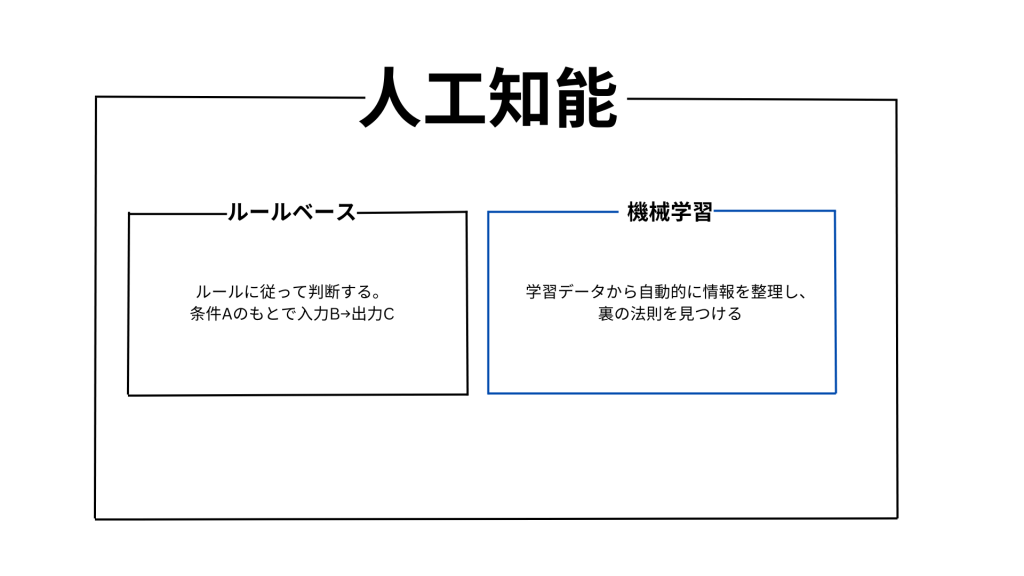
●ルールベース
人間があらかじめ設定した動作ルールに従って行動する仕組みです。「ある条件Aの下で、Bという入カデータが入ってきたら、©という出力を出しなさい」のような、連の命令(作ルール)が事前に決められており、AIはそれに思実に従って出力ずるだけです。
●機械学習
学習データをもとに、汎用的なルールやパターンを、学習というプロセスを介して導き出す手法です。「汎用的」という表現は、学習済みモデル(Trained Model)を用いて未知のデータに対する予測を導き出した結果、その予測精度がある程度担保されているということです。
例えば、AIを使って農作物の収穫時期を予測するプログラムを考えてみましょう。
この場合、天候データや気温、土壌の湿度といった要素が収穫時期に大きく影響を与えます。
ルールベースの方法を使うと、たとえば「気温が20度以上で、湿度が60%以上の日が7日続けば収穫可能」といった基準をあらかじめ人間が設定する必要があります。
このアプローチでは、専門家の知識や経験に基づいてルールを作り、それに従って収穫のタイミングを判断します。
一方で、機械学習を使う場合は、AIが大量の過去データから最適なタイミングを自ら見つけ出します。
天候パターンや土壌の状況を学習し、どの条件で収穫すれば最も良い結果が得られるかを自動的に判断するのです。
これが機械学習による「学習」のプロセスです。「学習データを用いること」と「学習のプロセスを必要とすること」です。
コンピュータに「人間らしい」認識能力・判断能力を持たせるためには、振る舞いの基準を定める必要があります。
2000年頃から、スマートデバイスの普及によりセンサー技術が進化し、日常的にデータの収集や分析ができるようになりました。これにより、いわゆる「IoT(モノのインターネット)」の時代が訪れ、多様な分野でデータ活用が進んできました。膨大なセンサーデータやユーザーデータを基に、機械学習の手法を活用することで、従来では発見できなかった隠れたパターンや最適な解決策が見つけられるようになってきました。
その中で、特に効果が大きい分野の一つがスマート農業です。近年、機械学習を使った作物の生育状態のモニタリングや予測技術が飛躍的に向上しています。例えば、農地に設置されたセンサーが日々の気温や湿度、日照量、土壌の栄養状態をデータとして集め、そのデータを基に最適な水やりのタイミングや肥料の量を予測できるようになりました。
これにより、従来の経験則に頼る農作業とは異なり、データに基づいた効率的かつ精密な農業が可能となっています。人間の経験だけでは把握しきれない膨大な量のデータを処理し、新たなパターンを発見し、その結果を基に即座に改善を行えるのが機械学習の強みです。
2.2 機械学習の仕組み
次は、機械学習における「学習」と「予測」の工程についてもっと具体的に見ていきましょう。
工程は次のような流れで行います。
- コンピュータが入力データを受け取り、モデルを学習させる
- 学習済みモデルを使って計算結果を出力する
上記のイメージを、機械学習で最も広く使われる「教師あり学習」を使用して下記に作成してみました。
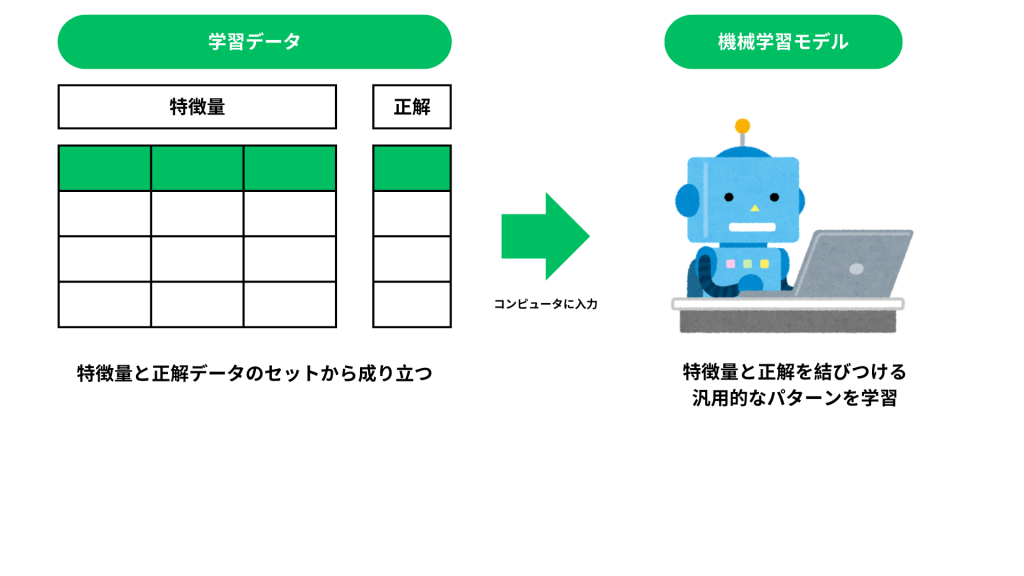
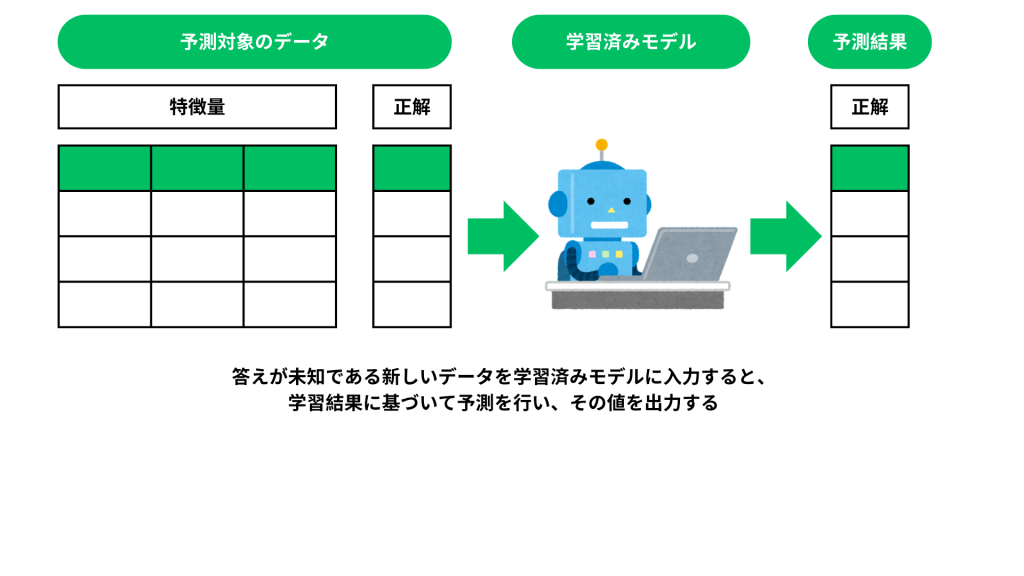
教師あり学習では、まず予測に役立つヒントとなる「入力データ」と、その結果として期待される「正解データ」の2つをコンピュータに与えます。入力データとは、予測や分類を行うために使う様々な要素(例:温度、湿度、風速など)で、これを「特徴量」と呼びます。そして、正解データは予測の答えとして用いるデータで、モデルが学習するためのお手本です。教師あり学習の目標は、この特徴量と正解の関係性を探り出し、新しいデータに対しても正しい答えを導き出せる法則を見つけることです。
この学習プロセスが完了したシステムを「モデル」と呼び、特に学習が済んだものを「学習済みモデル」と呼びます。学習済みモデルに新しい、答えがわからないデータを入力すると、これまでの学習によって得た法則に基づき、「正解に近い結果」を予測することができます。
モデルを現実の環境に実装する際には、テストデータを使ってその精度を検証することが不可欠です。もしモデルの精度が十分でない場合は、データの質や量、モデルの構造、学習の設定などを見直し、改善を加える必要があります。この試行錯誤を繰り返すことで、様々な状況でも使える汎用的なモデルを作り上げます。
この内容は、次に学ぶ「ディープラーニング」や、この講座でこの先学ぶ以下のテーマに深くつながります:
- 機械学習の手法の違い(教師あり学習、教師なし学習、強化学習など)
- 機械学習の精度検証プロセス
- 特徴量設計の難しさ
3.まとめ
これまで、人工知能(AI)の誕生から、その発展と応用について幅広く学んできました。
AIがどのようにして1956年のダートマス会議で一つの学問分野として確立され、その後の技術革新によって現代社会に深く根付いていったか、その歴史と定義を振り返ることで、AIの本質を理解することができたと思います。
特に、AIの中心的な技術である機械学習に焦点を当て、教師あり学習の仕組みとその意義について詳しく学びました。
私たちが与えた特徴量と正解データをもとに、AIが自ら法則を見つけ出し、新しいデータに基づいて適切な判断を行うプロセスは、AIの強力さを実感させるものでした。
また、モデルの精度を向上させるための試行錯誤や、実社会での活用に向けた準備の重要性にも触れ、AIの実用化までの道のりについても理解を深めました。
機械学習はAIの中でも特に重要な部分ですが、これから学ぶディープラーニングは、さらに一歩進んだ技術であり、近年のAIの飛躍的な進化を支える鍵となっています。
ディープラーニングの可能性を知れば知るほど、その魅力にワクワクするかもしれません。しかし、焦らずゆっくりと進んでいきましょう。
ディープラーニングも、基本的な考え方は機械学習と似ていますので、ここまで学んできた内容がしっかりと役立ちます。
次回から、いよいよディープラーニングに踏み込んでいきますが、まずは機械学習の基礎をしっかり押さえたことで、良い準備ができています。
これからさらに深い知識を得ることで、AIの世界がより広がるはずです。
楽しみながら、一歩ずつ理解を深めていきましょう!


