
依存更新が破綻しやすいのは、更新そのものが難しいというより、「いつ確認するか」「どこまで自動で通すか」「大量のPRをどう整理するか」のルールがないまま増えていくからです。DependabotやRenovateのような自動化ツールは、更新確認の手間を減らし、脆弱性対応や互換性維持の初動を速くしてくれます。ただし、自動でPRを出すだけでは逆にレビュー負荷が増え、放置や一括更新の事故につながることもあります。大切なのは、ツールを入れることではなく、頻度・まとめ方・自動マージ条件・例外時の戻し方まで含めて、チームで回る運用ルールに落とすことです。
関連: サプライチェーン攻撃とは?npmの依存汚染を前提に守る運用
1. 依存更新が破綻する理由
1-1. 放置すると何が起きるか(脆弱性・互換性・工数)
依存更新を放置すると、脆弱性対応が遅れるだけでなく、将来の互換性問題と更新工数が一気に重くなります。つまり、「今ラクをした分だけ、後で高くつく」領域です。
依存はアプリの外から入ってくるコードなので、時間が経つほど脆弱性修正やAPI変更が積み上がります。小さな更新を少しずつ追っていれば軽く済むものも、半年や1年放置すると、複数メジャー差分をまとめて追うことになり、テストも動作確認も一気に重くなります。さらに、サポート切れやツールチェーンのズレが起きると、更新したくてもすぐには上げられない状態になります。
現場でよくあるのは、「今の開発が忙しいから後でまとめてやる」という判断です。ただ、まとめてやる頃にはPR数も差分も大きくなり、結局もっと触りづらくなります。依存更新は“やるかやらないか”ではなく、“いつも少しずつ払うか、あとでまとめて大きく払うか”の違いだと考えると分かりやすいです。
1-2. “自動化しても地獄”になるパターン
依存更新は自動化すれば解決、とは限りません。ルールなしで自動PRだけ増やすと、今度はレビュー負荷と放置が増えて地獄になります。
たとえば、毎日大量のPRが飛んでくる、ライブラリごとに細かくPRが分かれすぎる、開発時間帯に通知が集中する、といった状態になると、チームはだんだん見なくなります。さらに、自動マージ条件が弱いと壊れた更新が入るし、逆に厳しすぎると全部人手待ちで詰まります。つまり、自動化ツールは“更新を作る”ところまでは助けてくれますが、“どう受け止めるか”までは別設計が必要です。
典型的な失敗は、「導入直後だけ盛り上がって、その後は依存更新PR専用の墓場ができる」ことです。これを防ぐには、PR数を減らすまとめ方、確認の時間帯、優先度のルールが必要です。自動化で重要なのは、PRを増やすことではなく、チームが処理できる量に整えることです。
2. ツールの役割(DependabotとRenovate)
2-1. 向き不向きと選び方
DependabotとRenovateはどちらも依存更新を自動化するツールですが、まず小さく始めたいならDependabot、細かく制御したいならRenovateが向きやすい、という捉え方が実務では分かりやすいです。
DependabotはGitHubとの統合が分かりやすく、比較的シンプルな設定で始めやすいのが利点です。一方、Renovateは設定の柔軟性が高く、グルーピング、優先度、ルール分岐、自動マージ条件などを細かく制御しやすいです。そのぶん、Renovateは最初に覚えることが少し多く、設定を雑に書くと逆に複雑化しやすい面もあります。
選ぶときは、「まず動かしてみたい」のか、「最初から運用の細かい制御までやりたい」のかで決めると迷いにくいです。チームに強い要件がなければ、今使っているプラットフォームとの相性や、メンバーが読める設定ファイルかどうかも重要です。高機能なほうが正義ではなく、チームが継続的に触れるほうが正解です。
2-2. まず揃える前提(テスト/CI/ロックファイル)
自動更新ツールを入れる前に、最低限そろっていないと運用が崩れやすい前提条件があります。それが、テスト、CI、ロックファイルです。
依存更新PRを安全に扱うには、少なくとも「通るかどうか」を自動判定できる仕組みが必要です。テストがない、またはCIが遅すぎて回らない状態だと、自動化しても人が全部確認するしかなくなります。また、ロックファイルが正として扱われていないと、PRごとの差分が曖昧になり、何が実際に更新されたのか追いにくくなります。
最初に確認したいのは、「依存更新PRで最低限どのチェックが走るか」「lockfile差分がレビューに出るか」「mainへ入る前にCI結果が見えるか」です。この土台がないままツールだけ入れると、PR生成マシンにはなっても、運用品質は上がりません。自動化の前提は、更新を受け止める足場があることです。
3. ルール設計(最小で回す)
3-1. 更新頻度(週次/日次)と時間帯
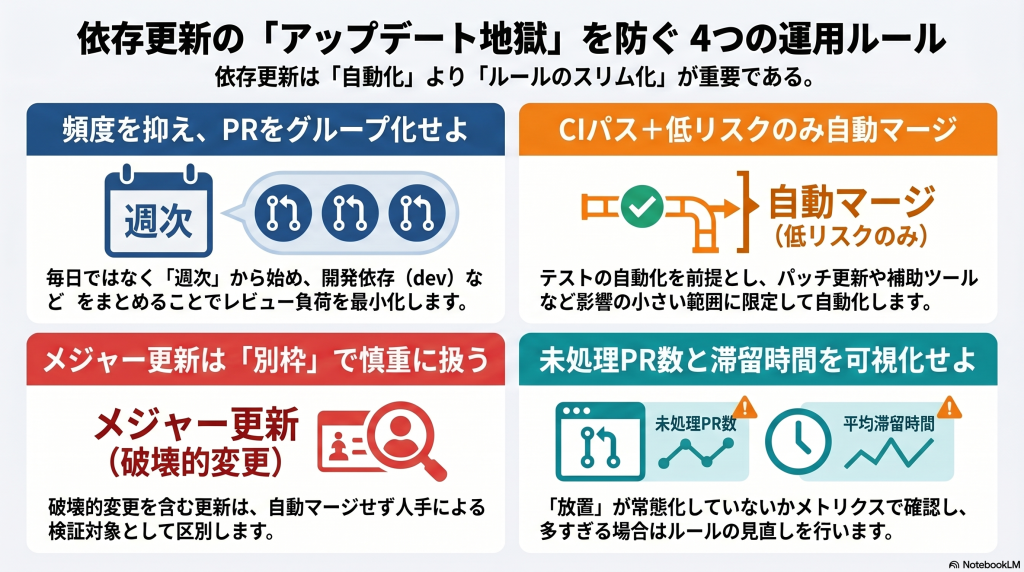
依存更新PRは、多ければ良いわけではなく、チームが処理できる頻度と時間帯に合わせることが大切です。最初は週次から始めると、運用を崩しにくいことが多いです。
日次更新は新鮮な差分を保ちやすいですが、チームのレビュー体制が弱いとPRが積み上がりやすくなります。週次なら、更新確認の時間を決めてまとめて見る運用にしやすいです。また、開発時間のど真ん中に大量通知が来ると集中を切りやすいので、朝早めや夜間にPR作成し、翌日のレビュー対象にする形も扱いやすいです。
最初の設定としては、「平日朝に週1回」「重大脆弱性だけは別で早めに出す」くらいが現実的です。日次にしたい場合も、まず1リポジトリで回してみて、未処理PR数や滞留時間を見てから広げるほうが安全です。頻度は理想論ではなく、レビューできる量に合わせるのが基本です。
3-2. grouping(まとめ方)と優先度
依存更新PRが多すぎるなら、更新を適切にまとめることがかなり効きます。1依存1PRのままだとレビュー数だけが増えやすく、チームがすぐ疲れます。
たとえば、開発依存をまとめる、lint系をまとめる、テスト系をまとめる、といった grouping をすると、PR数を減らしつつ意味のある単位で確認しやすくなります。一方で、全部を1本へまとめすぎると、どれが原因で壊れたか分かりにくくなります。つまり、まとめ方は“少なければよい”ではなく、“原因切り分けしやすい単位か”が大事です。
// 例:Renovate の考え方イメージ
{
"packageRules": [
{
"matchDepTypes": ["devDependencies"],
"groupName": "dev-dependencies"
},
{
"matchPackagePatterns": ["^eslint", "^prettier"],
"groupName": "lint-tools"
}
]
}この例では、開発依存やlintツールをまとめる意図があります。注意点は、アプリ本番動作に効く依存まで雑にまとめないことです。優先度としては、脆弱性修正やランタイム依存を高めに、開発補助ツールを低めにすると、レビューの集中先が分かりやすくなります。
4. 安全にマージする
4-1. automergeの条件(テスト/ラベル/レビュー)
automergeは便利ですが、条件なしで有効にすると事故の温床になりやすいです。安全に使うには、「どんな更新なら自動で通してよいか」をかなり明確にする必要があります。
一般的には、CIが全部通ること、対象が低リスクの依存であること、必要なラベルが付いていること、場合によってはレビュー済みであること、などを条件にします。たとえば、lintや型定義、テスト補助ツールのパッチ更新なら自動マージしやすいですが、フレームワーク本体やランタイム依存では慎重にしたほうがよいです。automergeは“人を不要にする機能”ではなく、“人が毎回見なくてよい範囲を限定する機能”と考えると扱いやすいです。
// 例:Dependabot / Renovate 共通の考え方イメージ
// automerge 条件
- CI が成功している
- パッチ更新のみ
- devDependencies のみ
- 特定ラベル(automerge-safe)が付いているこのように条件を明文化しておくと、「なぜこれは自動で入ったのか」を説明しやすくなります。注意点は、automerge対象を広げすぎることです。最初はかなり狭く始めて、事故が起きない範囲を少しずつ広げるほうが、チームの信頼も得やすいです。
4-2. breaking changeの扱い
依存更新運用で一番慎重に扱うべきなのが、breaking change を含む更新です。ここを通常更新と同じ流れにすると、壊れた状態を早く広めてしまいます。
メジャーバージョンアップは、API変更、設定ファイル変更、生成物の差、ビルドツールの相性ズレなどを含みやすいです。semverどおりに全部が安全に分類されるわけではありませんが、少なくともメジャー更新は別枠として扱ったほうがよいです。自動PRが来ても、そのまま自動マージではなく、リリースノート確認や手動検証の対象にするべきです。
実務では、「major更新は専用ラベルを付ける」「レビュー担当を固定する」「通常更新PRとは分けて処理する」といったルールが効きます。breaking changeは“頻繁ではないが重い”ので、少数でも丁寧に扱う設計にすると全体運用が安定します。
5. 運用が回る仕組み
5-1. 例外処理(止める/戻す/再開)
依存更新運用では、うまく回る通常時だけでなく、止める・戻す・再開する手順も決めておくことが重要です。ここがないと、1回事故が起きただけで自動化全体への信頼が下がりやすくなります。
たとえば、問題のある更新が混ざったら、そのルールだけ一時停止する、対象依存をpinする、最後の安全なlockfileへ戻す、といった手順が必要になります。また、壊れたあとに「今後その依存だけは手動運用に戻すのか」「一時停止後に再開するのか」まで決まっていないと、毎回その場の判断になります。例外処理は、運用を壊さないための逃げ道です。
最低限のルールとしては、「問題の更新を止める方法」「安全な状態へ戻す方法」「再開の条件」の3つを決めておくと扱いやすいです。たとえば、「ラベルでautomerge停止」「対象パッケージをignore」「修正版リリース後に再開」といった形です。運用で大事なのは、止まらないことではなく、止まっても戻れることです。
5-2. メトリクス(未処理PR数・滞留時間)
依存更新運用は、感覚ではなく、簡単なメトリクスで見ると改善しやすくなります。特に未処理PR数と滞留時間は、運用が回っているかを見るうえで分かりやすい指標です。
未処理PR数が増え続けるなら、更新頻度かグルーピングが合っていない可能性があります。滞留時間が長いなら、レビューの優先度が低すぎるか、PR数が多すぎるか、自動マージ条件が厳しすぎるかもしれません。全部を精密に測る必要はなくても、放置が当たり前になる前に気づける指標は持っておいたほうが良いです。
まずは「今開いている依存更新PRの数」「1週間以上残っているPRの数」だけでも十分です。月1回でも振り返れば、「多すぎるからグループを見直す」「重大依存だけ優先キューを作る」といった改善につなげやすくなります。自動化ツールは設定して終わりではなく、詰まり具合を見ながら調整するのが本来の使い方です。
6. まとめ:設定チェックリスト
DependabotやRenovateの運用が破綻しないためには、ツール導入より先に「どの頻度で」「どうまとめて」「どこまで自動で入れるか」を決めることが大切です。放置を防ぎたいのにPRが増えすぎる、怖くて触れない、という状態は、たいてい設定よりルールの問題です。
最小のチェックリストとしては、次の観点を持っておくとかなり安定します。更新頻度はチームが見られる量か、PRは意味のある単位でgroupingされているか、lockfile差分がレビューされるか、CI成功を自動マージ条件にしているか、major更新を別扱いにしているか、止める/戻す/再開の例外手順があるか、未処理PR数と滞留時間を見ているか、の7点です。
依存更新運用で一番避けたいのは、「自動化ツールは入っているのに、誰も見ていない」状態です。逆に言えば、ルールが小さくても回っているなら十分価値があります。DependabotでもRenovateでも、成功条件は“高機能な設定”ではなく、“チームが処理できる量に整えられていること”です。
7. 参考リンク
- GitHub Dependabot documentation
https://docs.github.com/en/code-security/dependabot - Renovate documentation
https://docs.renovatebot.com/ - SemVer specification
https://semver.org/



