
コンテナ脆弱性スキャンとは、アプリ本体だけでなく、ベースイメージに含まれるOSパッケージやライブラリまで調べて、既知の脆弱性が混ざっていないかを確認することです。コンテナは「一度作れば同じものをどこでも動かせる」反面、危険な部品もそのまま配布しやすいため、ビルド時点で止める仕組みが重要になります。CIゲートが必要なのは、手元の確認だけでは見落としや運用漏れが起きやすく、重大な脆弱性を含んだイメージがそのままリリースされるのを防ぎにくいからです。
関連: Dependabot/Renovate運用のコツ:アップデート地獄を防ぐルール設計
1. コンテナ脆弱性スキャンとは
1-1. 何をスキャンしているか(OS/ライブラリ/イメージ)
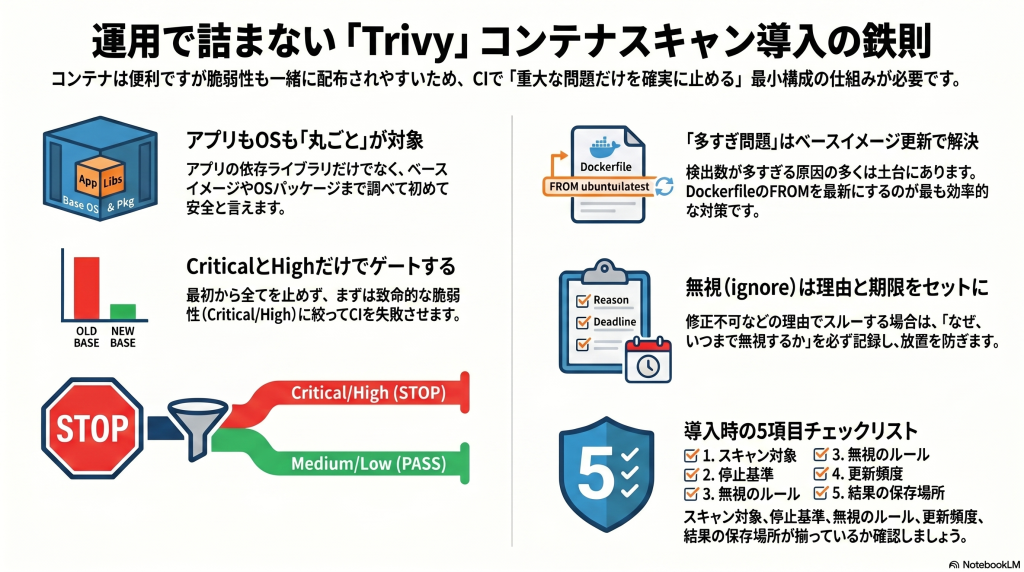
コンテナ脆弱性スキャンは、コンテナイメージの中に入っている部品を調べて、既知の脆弱性がないか確認する作業です。見ている対象はアプリコードそのものだけではなく、OSパッケージや依存ライブラリ、ベースイメージ全体に広がります。
たとえば、Node.jsアプリのコンテナなら、package.json 系の依存だけでなく、DebianやAlpineのOSパッケージ、opensslのような共通ライブラリ、ベースイメージに元から入っているツール群も対象になります。つまり、アプリ開発者が直接追加したものだけでなく、「便利だから使っている土台」も一緒に調べるのがコンテナスキャンです。ここを見ないと、アプリ依存は安全でもベースイメージ側に重大な問題が残ることがあります。
実務では「自分が書いたコードじゃないから後回し」となりがちですが、実際に配布されるのはコンテナイメージ全体です。チェック観点としては、「アプリ依存だけを見て満足していないか」「ベースイメージやOS層もスキャン対象に入っているか」をまず確認すると、見落としを減らしやすくなります。
1-2. “検出=即アウト”にならない理由(運用前提)
脆弱性スキャンでは、検出されたものが全部そのまま“即アウト”になるわけではありません。大事なのは、検出結果をどう評価して、どこで止めるかという運用ルールです。
なぜなら、スキャン結果には「今すぐ危険なもの」と「理論上は載っているが実害が低いもの」が混ざるからです。たとえば、修正版がまだ出ていない脆弱性、到達しないコンポーネント、実行されない補助パッケージなども検出されることがあります。ここで全部を即失敗にすると、現場はすぐに“赤だらけで誰も見ない”状態になりやすいです。
そのため、最初の運用では「どの重大度でCIを落とすか」「例外はどこへ記録するか」「いつまでに直すか」を決めるのが重要です。スキャンは技術だけで完結せず、最終的には運用ルールがないと続きません。つまり、Trivyの導入はツール導入というより、判定基準づくりでもあります。
2. Trivyの基本(できること)
2-1. どこで使うか(ローカル/CI)
Trivyは、ローカルでもCIでも使える脆弱性スキャナです。最初は手元で結果の見え方を確認し、その後CIへ載せてゲートにする流れが分かりやすいです。
ローカルで使う利点は、Dockerfileやベースイメージを変えた直後に、どんな結果が出るかをすぐ確認できることです。一方、CIで使う利点は、全員が同じ条件で必ずチェックされることです。手元だけだと「見た人だけ気づく」運用になりやすいですが、CIに組み込むと、リリース前の最低ラインとして機能しやすくなります。
まずはローカルで1回流して、結果の量や重大度の傾向を見てからCIへ持ち込むと、いきなりパイプラインを真っ赤にしにくいです。使い始めの段階では、「開発者が自分の変更で何が増えたかを確認する場所」と「最終的に止める場所」を分けて考えると混乱しにくくなります。
2-2. 出力形式と見るポイント
Trivyの出力は、人が読むための一覧にも、CIで処理するための機械向け形式にもできるのが特徴です。最初はテーブル表示で十分ですが、運用ではJSONやSARIFのような形式も役立ちます。
人が見るときは、どのパッケージに、どの重大度の脆弱性が、修正版ありかなしか、という点を先に見るのが基本です。CIやGitHub連携では、結果を機械的に扱える形式へ出して、レポートやアラートへつなげやすくします。つまり、表示形式は目的で変わり、人間向けと自動連携向けを分けて考えると整理しやすいです。
最初に見るポイントとしては、「Critical/High がいくつあるか」「修正版があるか」「どの層で見つかったか」の3つで十分です。細かいCVSSや説明文を全部追う前に、まず“今止めるべきものか”を判断する視点を持つと、結果が多くても見やすくなります。
3. CIでゲートする最小構成
3-1. 重大度(Severity)で落とす基準
CIで最初に決めるべきなのは、どの重大度でビルドを落とすかです。最小構成なら、まずはCriticalとHighだけをゲート対象にするのが現実的です。
最初からMediumやLowまで全部失敗にすると、結果が多すぎて現場が処理しきれなくなることがあります。逆に、何も止めないとCIゲートの意味が薄くなります。そのため、まずは「放置すると危険度が高い層」に絞って止め、運用が回ってきたら範囲を見直す進め方が安定します。
# ローカル例
trivy image --severity HIGH,CRITICAL --exit-code 1 my-app:latest# GitHub Actions の最小イメージ
- name: Scan image with Trivy
uses: aquasecurity/trivy-action@master
with:
image-ref: my-app:latest
severity: HIGH,CRITICAL
exit-code: '1'
ignore-unfixed: trueこの設定では、High/Critical が見つかったときだけCIを失敗にしています。注意点は、最初から ignore-unfixed をどう扱うかを決めておくことです。修正版がまだ出ていないものまで全部止めると詰まりやすい一方で、無視しすぎると危険を見落としやすくなるため、チームで基準を揃える必要があります。
3-2. 例外(ignore)の管理ルール
スキャン運用では、例外をゼロにするより、例外を雑に増やさないことのほうが重要です。ignoreは必要な場面がありますが、ルールなしだと“見たくない結果を消す機能”になりやすいです。
たとえば、修正版が未提供でどうしても今は直せない、実行経路に乗らない、別の対策でリスク低減済み、といった事情なら一時的な例外はあり得ます。ただし、誰が、何を、いつまで無視するのかが残っていないと、例外が永久に残ります。ignoreは運用の逃げ道ですが、逃げ道こそ記録が必要です。
# .trivyignore のイメージ
CVE-2024-12345
CVE-2024-99999最低限のルールとしては、「ignoreする理由をPRやチケットに書く」「期限や見直し日を持つ」「脆弱性IDだけでなく判断根拠を別途残す」が有効です。ファイルに書いて終わりにせず、レビュー可能な場所で理由を追えるようにしておくと、“なぜ無視しているのか不明”な状態を防ぎやすくなります。
4. “多すぎ問題”の現実解
4-1. ベースイメージ更新の運用
Trivyを入れて最初にぶつかりやすいのが、結果が多すぎて何から手を付ければよいか分からない問題です。このとき一番効きやすいのが、ベースイメージ更新の運用を整えることです。
実際には、アプリコードよりもベースイメージ側のOSパッケージ由来で大量に検出されることが少なくありません。古い node ベースや更新頻度の低いイメージを使っていると、そこだけで大量のHigh/Mediumが出ます。つまり、“結果が多い”原因がアプリ依存ではなく土台側にあるケースはかなり多いです。
現実解としては、「定期的にベースイメージを上げる」「より小さく保守されたイメージを選ぶ」「不要なパッケージを減らす」の3つを意識すると効果が出やすいです。Trivy結果を眺めるだけでなく、Dockerfileの FROM を見直す習慣を持つと、多すぎ問題を根本から減らしやすくなります。
4-2. 優先順位付け(KEV/露出/到達可能性)
結果が多いときは、全部を同じ重みで扱わず、優先順位を付けるのが現実的です。重大度だけでなく、悪用状況や公開露出、実際の到達可能性を見ると、対応順が決めやすくなります。
たとえば、実際に悪用が確認されている脆弱性、外部公開サービスで到達しやすいコンポーネント、アプリが実際に使っている経路に乗るものは優先度が高いです。一方、ビルド時だけ使う補助ツールや、到達しないライブラリは、重大度が高くても直ちに最優先とは限りません。ここで全部を平等に見ると、現場は処理しきれなくなります。
最初の優先順位づけとしては、「Critical/High」「外部公開」「修正版あり」を重ねて見るだけでも十分です。さらに余裕があれば、実際の悪用情報や到達可能性も加味すると判断がしやすくなります。Trivyは検出の入口であって、最終判断は“現場のリスク”とつなげて行うものだと考えると扱いやすいです。
5. SBOMとの関係
5-1. SBOMとスキャンの役割分担
SBOMとTrivyのようなスキャンは似て見えますが、役割はかなり違います。簡単に言うと、SBOMは「何が入っているか」を整理し、スキャンは「それに既知の問題があるか」を確認します。
SBOMは部品表なので、コンテナや成果物に何のパッケージ・ライブラリが含まれているかを追跡するのが主な役目です。一方、Trivyはその部品情報やイメージ内容を元に、脆弱性データベースと照合して危険度を出します。つまり、SBOMが台帳、スキャンが照合と判定の役割に近いです。
実務では、「SBOMがあるからスキャン不要」「スキャンしているからSBOM不要」ではなく、両方を役割分担で使うと整理しやすいです。SBOMは影響調査や説明責任に強く、Trivyは日々のゲートや検知に強い、という分担で考えると導入の意味が見えやすくなります。
5-2. 監査・説明責任の作り方
CIゲートを運用するなら、「なぜ止めたか」「なぜ通したか」を後から説明できる状態を作ることが大切です。ここでSBOMやスキャン結果の保存が効いてきます。
監査や障害振り返りでは、「このイメージに何が入っていたか」「その時点でどんな脆弱性が検出されていたか」「なぜ例外扱いしたか」を説明する必要が出ます。Trivyの結果を一時的なCIログだけにすると、後から追いにくくなります。結果や例外判断を成果物やチケットとひも付けて残しておくと、説明責任を果たしやすくなります。
最小構成としては、「どのイメージをスキャンしたか」「どの重大度で落としたか」「ignoreした脆弱性と理由」を残すだけでも十分です。完璧な監査台帳を最初から作るより、まずは“判断の痕跡が残る”状態を作ることが重要です。
6. まとめ:導入チェックリスト
Trivy導入で最初に目指すべきなのは、全部の脆弱性を一気になくすことではなく、重大なものをCIで止め、例外を記録し、多すぎる結果に優先順位を付けられる状態を作ることです。スキャンは検出そのものより、運用のほうが難しいので、最初から小さく始めるほうが成功しやすいです。
導入チェックリストとしては、「何をスキャン対象にするかを決めたか」「CIでどの重大度を落とすか決めたか」「ignoreの理由と期限を残せるか」「ベースイメージ更新の担当と頻度があるか」「結果を保存して後から追えるか」の5点が最低ラインです。これがあるだけで、“入れたけど誰も見ないスキャン”になりにくくなります。
Trivyは強力ですが、設定して終わりではありません。大事なのは、スキャン結果をチームが処理できる量にし、止める基準と例外ルールを明確にすることです。CIゲートは厳しさそのものより、継続して回せることが価値になります。
7. 参考リンク
- Trivy 公式ドキュメント
https://trivy.dev/latest/ - Trivy GitHub Actions
https://github.com/aquasecurity/trivy-action - Trivy SBOM 関連ドキュメント
https://trivy.dev/latest/docs/supply-chain/sbom/



