1.はじめに
どうも、エンジニアのKです。
最近、進化するAI開発の物体検出の分野において、YOLOがリアルタイム物体検出の分野で最も注目される技術となっています。
その理由は、計算コストと検出性能の絶妙なバランスにあります。
これまでの研究では、YOLOのアーキテクチャや最適化、データ拡張などが探求され、多くの進展が見られました。
しかし、YOLOの課題も明らかになっています。
それは、ポストプロセッシングに使用される非最大抑制(NMS)がエンドツーエンドでの展開を妨げ、推論のレイテンシを増加させることです。
さらに、YOLOの設計にはまだ改善の余地があり、計算の無駄が目立つため、性能をさらに引き上げることができます。
そこで新たに発表されたYOLOv10は、YOLOの性能と効率をさらに向上させる新たなアプローチを提案しました。
まず、NMSを使わずにトレーニングを行うための「一貫した二重割り当て」を導入しました。
これにより、競争力のある性能を保ちつつ、推論のレイテンシを低く抑えることができるようになりました。
さらに、YOLOv10では、YOLOの設計において、効率性と精度の両面から徹底的に最適化を進める「包括的な効率-精度駆動型モデル設計戦略」を提案しており、この戦略により、計算のオーバーヘッドを大幅に削減し、モデルの能力を大きく向上させました。
この努力の成果として、YOLOの新世代「YOLOv10」での広範な実験によると、YOLOv10はさまざまなモデルスケールで最先端の性能と効率を実現しました。
たとえば、YOLOv10-SはCOCOデータセットで、同じAPを持つRT-DETR-R18よりも1.8倍速く、パラメータとFLOPsがそれぞれ2.8倍少なくなっています。
また、YOLOv9-Cと比べると、YOLOv10-Bは46%のレイテンシ削減と25%のパラメータ削減を実現しています。
1-1.Yoloとは
YOLOはリアルタイムオブジェクト検出アルゴリズムです。YOLO(You Only Look Once)の名前通り、このアルゴリズムでは検出窓をスライドさせるような仕組みを用いず、画像を一度CNNに通すことで、オブジェクトを検出することができます。
YOLOアルゴリズムで使用する教師データは少々複雑であるため、アルゴリズムのイメージを把握することは教師データの構造を理解することにも役立ちます。
2.物体検出とYOLO
リアルタイム物体検出は、コンピュータビジョン分野で常に注目されている研究領域です。
この技術は、画像内の物体のカテゴリと位置を低レイテンシで正確に予測することを目指しています。自動運転車やロボットナビゲーション、物体追跡など、さまざまな実用的なアプリケーションで広く採用されています。
最近の研究では、リアルタイム検出を達成するためにCNNベースの物体検出器が開発されています。
その中でもYOLO(You Only Look Once)は、そのパフォーマンスと効率のバランスが優れているため、人気が高まっています。
YOLOの検出パイプラインは、モデルのフォワードプロセスとNMS(非最大抑制)ポストプロセッシングの2つの部分で構成されています。
しかし、これらの部分にはまだ改善の余地があり、精度とレイテンシの最適なバランスが取れていません。
具体的には、YOLOは通常、トレーニング中に一対多のラベル割り当て戦略を採用します。
これにより、1つの地上真実物体が複数のポジティブサンプルに対応しますが、このアプローチは推論中にNMSが最適な予測を選択する必要があり、推論速度が遅くなり、NMSのハイパーパラメータに対して敏感になります。
これにより、YOLOが最適なエンドツーエンドの展開を達成するのが難しくなります。
この問題に対処するためのアプローチの一つは、最近導入されたエンドツーエンドのDETR(Detection Transformer)アーキテクチャを採用することです。
例えば、RT-DETRは効率的なハイブリッドエンコーダと不確実性最小のクエリ選択を提示し、DETRをリアルタイムアプリケーションの領域に推進しています。
しかし、DETRの展開には複雑さが伴い、精度と速度の最適なバランスを達成するのは難しいです。
もう一つのアプローチは、CNNベースの検出器のエンドツーエンド検出を探求することです。
これには通常、一対一の割り当て戦略を利用して冗長な予測を抑えることが含まれますが、追加の推論オーバーヘッドが発生するか、パフォーマンスが最適でないことが多いです。
さらに、YOLOのモデルアーキテクチャ設計も基本的な課題となっています。
その課題に対し、より効率的で効果的なモデルアーキテクチャを実現するために、研究者たちはさまざまな設計戦略を探求しています。
バックボーンには、DarkNetやCSPNet、EfficientRep、ELANなど、特徴抽出能力を向上させるための主要な計算ユニットが提案されており、ネック部分には、PAN、BiC、GD、RepGFPNなど、マルチスケール特徴融合を強化するためのアプローチが探求されています。
さらに、モデルスケーリング戦略や再パラメータ化技術も調査されています。
しかし、これらの努力にもかかわらず、YOLOのさまざまなコンポーネントの効率性と精度に関する包括的な検査はまだ不足しています。
そのため、YOLOには依然として大きな計算の冗長性があり、パラメータの利用効率が低く、効率が最適でない結果が生じています。この結果、モデルの能力が制約され、性能向上の余地が大いに残されています。
3.YOLOv10のすごいところ
Consistent Dual Assignmentsによる NMS-free な学習
YOLOv10のアイデアは、上記図に示すように、2つの検出ヘッドを用いることです。
- One-to-many ヘッド: 学習時に豊富な教師信号を与える役割。1つの物体に対して複数の候補を割り当てる。
- One-to-one ヘッド: 推論時に高速な処理を実現する役割。1つの物体に対して最適な1つの候補のみを出力する。
学習時は2つのヘッドを同時に学習し、推論時はOne-to-oneヘッドのみを使用します。
これにより、NMSが不要となり、高速でEnd-to-Endな推論が可能になります。
さらに、Consistent Matching Metricを導入することで、2つのヘッドの学習の整合性を高めています。
具体的には、One-to-oneヘッドの教師信号が、One-to-manyヘッドの最適解に近づくように設計されています。
効率性と精度を重視したモデル設計
提案手法では、YOLOアーキテクチャの各コンポーネントを効率性と精度の観点から最適化しています。
効率性の改善
- 軽量な分類ヘッド: 回帰ヘッドに比べて分類ヘッドの計算量が大きいことに着目し、Depthwise Separable Convolutionを用いて軽量化。
- Spatial-channel decoupled downsampling: ダウンサンプリングの際、チャネル数の増加と解像度の削減を分離することで、効率的な特徴量の圧縮を実現。
- Rank-guided block design: 特徴量のランクに基づいて、冗長な計算の多いブロックをよりコンパクトなものに置き換える。
精度の改善
- Large-kernel convolution: 受容野を広げるために、一部の層でカーネルサイズの大きな畳み込みを導入。
- Partial self-attention (PSA): Self-attentionの計算コストを抑えつつ、グローバルな特徴の統合を可能にするPSAモジュールを提案。
4.YOLOV10と他のモデルの比較
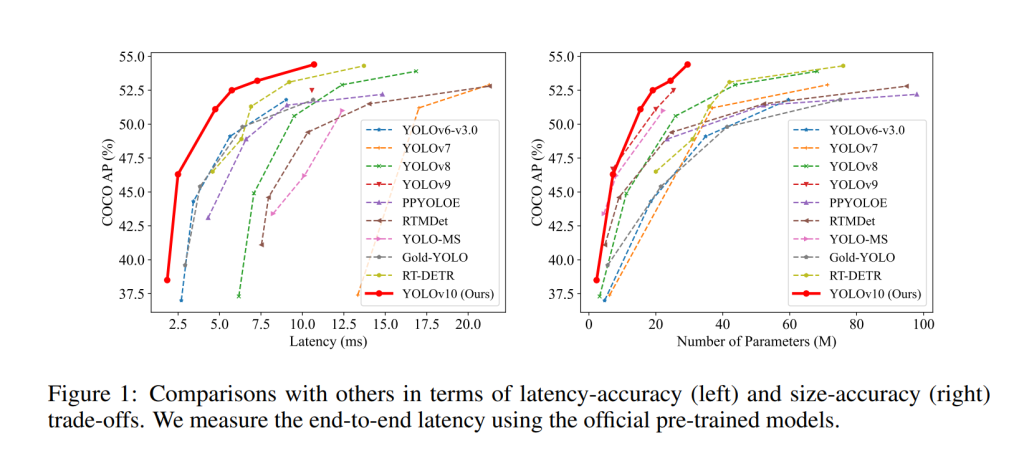
論文によるとCOCOデータセットでの評価実験では、以下のような結果が得られたとされています。
- 同程度の精度では、YOLOv10-SはRT-DETR-R18の1.8倍の速度を達成。
- 同程度の速度では、YOLOv10-XはYOLOv8-Xより0.5% AP高精度。
- YOLOv10-BはYOLOv9-Cと同等の精度で、46%の速度向上を達成。
4.まとめ
進化の止まらない物体検出分野は、今となっては研究としてだけでなく、日常生活の至るところでも物体検知が使われているところもあり、これからもどんどん世の中に進出をしてくるであろうと考えています。
この先もどんどん新たな研究で色々な物体検出技術が生み出されていくとは思いますが、それは確実に人類の大きな文明の飛躍に一役買うものだと筆者は望んでいます。