
はじめに
近年、深層学習(ディープラーニング)は急速に発展し、その応用範囲は画像認識、自然言語処理、医療、創作分野など多岐にわたります。その中でも「深層生成モデル(Deep Generative Models)」は特に注目される分野の一つです。
深層生成モデルは、データの背後にある確率分布を学習し、新しいデータを生成するために用いられます。これにより、リアルな画像の生成、文章の作成、音楽の作曲、3Dモデルの生成など、さまざまな創造的なタスクが可能になります。
本カリキュラムでは、深層生成モデルの基本的な概念を理解し、代表的な手法である 変分オートエンコーダ(VAE) と 敵対的生成ネットワーク(GAN) について深く掘り下げます。

深層生成モデルとは
1. 生成モデルの基本概念
機械学習には、大きく分けて 識別モデル(Discriminative Model) と 生成モデル(Generative Model) があります。
- 識別モデル は、入力データがどのクラスに属するかを分類するモデルであり、画像認識や音声認識などに活用されます。
- 生成モデル は、データの分布を学習し、それに基づいて新しいデータを生成するモデルです。
例えば、識別モデルが「犬か猫かを判別するモデル」だとすれば、生成モデルは「犬や猫の画像をゼロから生成するモデル」です。
2. 深層生成モデルの特徴
深層生成モデルは、単純な統計的な生成モデルとは異なり、ニューラルネットワークを活用することで、より複雑なデータ分布を学習し、高品質なデータを生成することが可能です。代表的な手法には以下のようなものがあります。
- 変分オートエンコーダ(VAE)
- 敵対的生成ネットワーク(GAN)
- フロー型モデル(Normalizing Flow)
- 拡散モデル(Diffusion Model)
本カリキュラムでは、VAEとGANの2つに焦点を当てて詳しく解説します。
変分オートエンコーダ(VAE)
1. オートエンコーダ(Autoencoder, AE)とは?
VAEを理解するには、まず オートエンコーダ(Autoencoder, AE) の基本的な仕組みを理解する必要があります。オートエンコーダは、ニューラルネットワークを用いてデータを低次元の潜在空間に圧縮し、そこから元のデータを復元することを目的としたモデルです。
1.1 オートエンコーダの構造
オートエンコーダは、主に次の 2つのニューラルネットワーク で構成されます。
- エンコーダ(Encoder)
- 入力データ x を低次元の潜在変数 z に変換する。
- これにより、元のデータの本質的な特徴を抽出することができる。
- デコーダ(Decoder)
- エンコーダによって得られた z を元のデータ x に復元する。
1.2 オートエンコーダの学習
オートエンコーダは、入力データ x と、復元データ x^ の間の誤差(再構成誤差)を最小化するように学習します。
一般的には以下の損失関数が用いられます。
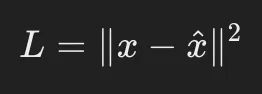
これは単純な 二乗誤差(Mean Squared Error, MSE) であり、入力データをどれだけ正確に復元できるかを評価します。
しかし、通常のオートエンコーダには 「潜在空間の制約がない」 という課題があります。
潜在変数 z が自由に学習されるため、データの確率的な分布を考慮せず、新しいデータを生成するには適していません。
この問題を解決するのが、次に紹介する 変分オートエンコーダ(VAE) です。
2. 変分オートエンコーダ(VAE)の仕組み
VAEは、通常のオートエンコーダとは異なり、潜在変数 z を 確率的な分布 としてモデル化し、新しいデータの生成を可能にします。
2.1 潜在変数の確率分布化
通常のAEでは、エンコーダは 1つの固定された潜在変数 zを出力します。
しかし、VAEでは、潜在変数を 確率分布 として捉え、エンコーダの出力を以下の2つのパラメータで表現します。
- 平均(Mean, μ)
- 分散(Variance, σ2)
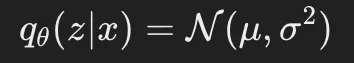
ここで、エンコーダは 入力データ xから 潜在変数の分布(ガウス分布) を学習し、その確率分布からサンプリングを行います。
この確率的な潜在変数を利用することで、VAEは データの多様性を学習し、新しいデータを生成 できるようになります。
2.2 サンプリングと再構成
VAEでは、エンコーダが出力する μと σ2 から、潜在変数 z をサンプリングする必要があります。
しかし、通常のニューラルネットワークは確率的なサンプリングの操作を直接扱えません。
この問題を解決するために、VAEでは 再パラメータ化トリック(Reparameterization Trick) を使用します。
再パラメータ化トリックとは?
サンプリングを直接行うのではなく、以下のように 確率分布からノイズ ϵ\epsilonϵ を導入して計算する ことで、ニューラルネットワークが学習可能な形式に変換します。

この変換により、潜在変数 z の学習が可能になります。
- ϵは標準正規分布(平均0, 分散1)からサンプリング
- これを μとσにスケーリングして z を生成
この z をデコーダに入力し、データを再構成します。
2.3 損失関数の最適化
VAEの損失関数は、以下の 2つの誤差 から構成されます。
- 再構成誤差(Reconstruction Loss)
- 生成したデータ x^が元のデータ xに近いかを評価
- MSEやクロスエントロピーが一般的に使われる
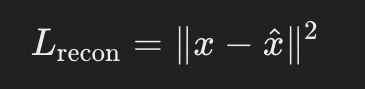
- KLダイバージェンス(Kullback-Leibler Divergence)
- 潜在変数の分布 qθ(z∣x)を標準正規分布 p(z)=N(0,I)に近づけるための正則化項
- これにより、潜在空間がスムーズになり、新しいデータをサンプリングしやすくなる

最終的なVAEの損失関数
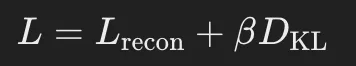
ここで βは、再構成誤差とKLダイバージェンスのバランスを調整するハイパーパラメータです(β-VAEなどの手法では、これを調整することで制約を強化できます)。
2.4 VAEのメリットと応用
✅ メリット
- 確率的生成が可能: ノイズから多様なデータを生成できる
- 滑らかな潜在空間: 連続的にデータを補間できる(例: 顔の画像を徐々に変化させる)
- 教師なし学習が可能: ラベルなしデータから表現を学習できる
✅ 応用例
- 画像生成(手書き数字、顔画像)
- 異常検知(異常なデータが通常分布から逸脱することを利用)
- データ補間(連続的な変換を可能にする)
敵対的生成ネットワーク(GAN)
1. GANの基本概念
1.1 GANとは?
GAN(Generative Adversarial Network, 敵対的生成ネットワーク)は、2014年に Ian Goodfellow らによって提案された画期的な生成モデルです。
GANの最大の特徴は、「2つのニューラルネットワークが互いに競争しながら学習する」 という仕組みにあります。
この2つのネットワークとは、次の通りです。
- 生成器(Generator, G):
ランダムなノイズから、できるだけ本物らしいデータを生成するネットワーク。 - 識別器(Discriminator, D):
入力データが本物(訓練データ)か、生成器が作った偽物かを判別するネットワーク。
生成器と識別器はゲーム理論的な関係(ミニマックスゲーム)にあり、互いに競争することで精度が向上していく のがポイントです。
- 生成器の目的:
識別器を騙せるほどリアルなデータを作る。 - 識別器の目的:
生成データと本物データをしっかり区別する。
1.2 GANの数学的定義(ミニマックスゲーム)
GANの目的は、生成器 GGG が 本物のデータと区別できない偽データを作る ことです。
そのために、GANは 損失関数(目的関数)を最適化する ことで学習を進めます。
GANの損失関数(ミニマックスゲームの定式化)は次のようになります。
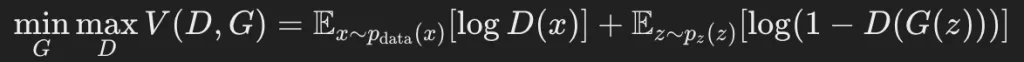
ここで、
- x∼pdata(x):
本物のデータの分布 - z∼pz(z):
生成器が受け取るランダムなノイズの分布(通常は正規分布) - D(x):
識別器が「入力データが本物である確率」として出力する値 - G(z):
生成器がノイズ zzz から生成したデータ
この数式の意味は、識別器 Dは本物データ xを正しく判別しつつ、生成データ G(z)を偽物だと認識しようとする ということです。
一方、生成器 Gは識別器 Dを騙し、本物に近いデータを生成しようとする という構図になっています。
1.3 GANの学習の仕組み(簡単な説明)
GANの学習では、次のような対抗戦が繰り広げられます。
- まず識別器を学習する
- 本物のデータと生成器が作ったデータを見て、「どちらが本物か」を判別できるようにする。
- 次に生成器を学習する
- 生成器は、識別器を騙せるような「よりリアルなデータ」を作るように改善される。
- このプロセスを繰り返す
- 生成器と識別器が互いに競争することで、最終的に「非常にリアルなデータ」を生成できるようになる。
2. GANの学習プロセスの詳細
GANの学習は、次のステップを繰り返して行われます。
2.1 生成器の学習
- 入力: ランダムなノイズ z
- 処理: 生成器 Gはノイズを本物らしいデータ G(z)に変換
- 出力: 偽のデータ
- 目的: 識別器を騙せるように、本物らしいデータを作成
2.2 識別器の学習
- 入力: 本物データ xと生成データ G(z)
- 処理: 識別器 Dは、それが本物か偽物かを判定
- 出力: 0(偽物)または1(本物)
- 目的: できるだけ正確に、本物と偽物を見分ける
この学習を何度も繰り返すことで、最終的に 生成器が非常にリアルなデータを作れるようになる のです。
3. GANの応用例
GANは非常に強力な技術で、さまざまな分野で活用されています。
3.1 画像生成
- StyleGAN:
高解像度の顔画像を生成するGANの一種。人間の顔を「ゼロから」作り出すことができる。 - BigGAN:
高品質な画像生成が可能な大規模GANモデル。
3.2 画像の高解像度化(Super-Resolution)
- SRGAN(Super-Resolution GAN):
低解像度の画像を高解像度に変換する技術。- 例: ぼやけた画像をくっきりさせる技術(古い写真の復元など)。
3.3 テキストから画像を生成
- DALL·E(OpenAI):
テキストの説明をもとに画像を生成できるモデル。- 例: 「宇宙を飛ぶ猫の絵を描いて」と指示すると、AIがそれに応じた画像を作成。
3.4 ゲーム・映像分野
- キャラクターの自動生成:
ゲーム内のNPCの顔や服装を自動生成する。 - 環境シミュレーション:
仮想環境をリアルに再現し、ゲームや映画の背景生成に活用。
4. GANの課題と改良手法
4.1 GANの課題
GANは非常に強力な技術ですが、いくつかの問題点があります。
- モード崩壊(Mode Collapse)
- 生成器が「特定のパターンのデータばかりを作ってしまう」問題。
- 例えば、手書き数字の生成で「8」しか作れなくなることがある。
- 学習の不安定性
- 生成器と識別器のバランスが崩れると、学習が進まなくなる。
- 例えば、識別器が強すぎると、生成器が「諦めて」しまう。
- 評価指標が曖昧
- 生成されたデータが「どれだけ本物らしいか」を評価する明確な指標がない。
4.2 改良版GAN
これらの問題を解決するために、多くの改良版GANが登場しています。
✅ WGAN(Wasserstein GAN): 学習の安定性を向上
✅ DCGAN(Deep Convolutional GAN): CNNを導入して画像生成を強化
✅ StyleGAN: 生成画像の品質を大幅に向上
まとめ
本カリキュラムでは、深層生成モデルの基本概念を学び、特にVAEとGANの仕組みと応用について詳しく解説しました。
- VAEは確率分布を学習し、潜在空間を正則化することで新しいデータを生成する。
- GANは生成器と識別器の競争を利用し、よりリアルなデータを生み出す。
今後、深層生成モデルの技術はさらに進化し、新たな応用が広がるでしょう。
次のステップとして、実際にVAEやGANを実装し、モデルを訓練してみることをおすすめします。

