転移学習は、人工知能(AI)と機械学習(ML)の分野において非常に重要な技術の一つです。
この技術は、特定のタスクで学習した知識を別のタスクに適用することにより、学習過程を効率化し、データが少ない状況でも高いパフォーマンスを達成することを可能にします。
転移学習とは
転移学習は、ある問題領域で学習したモデルの一部または全体を、新たながら関連する問題に適用することです。
主に、モデルが新しいタスクで必要とする知識の一部を、すでに学習済みのデータから抽出して利用します。
このプロセスでは、ソースタスクとターゲットタスク間で知識が「転移」されることからこの名が付けられています。
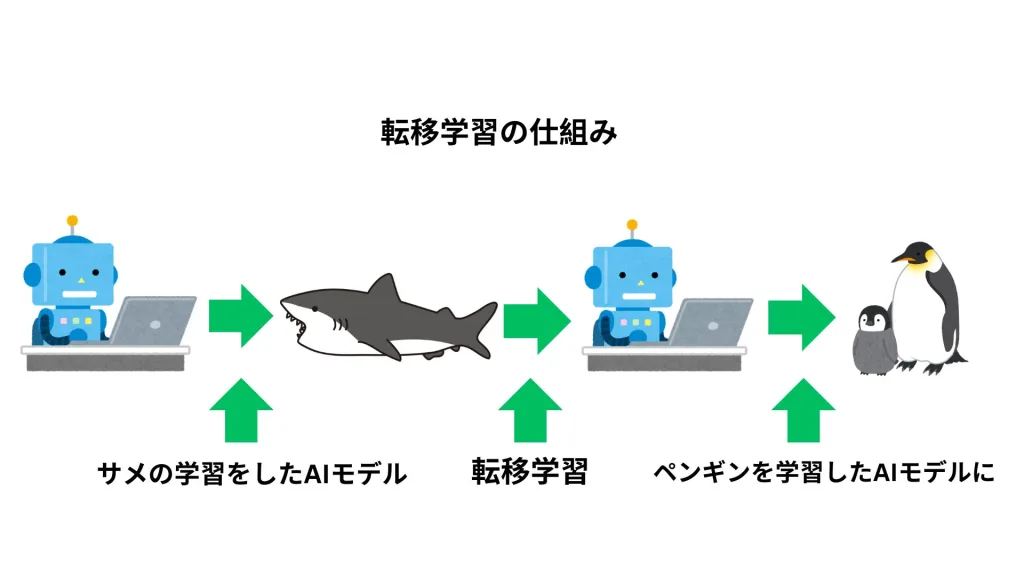
転移学習とファインチューニングの違い
転移学習とファインチューニングは密接に関連していますが、異なるアプローチを持ちます。
転移学習は、一般的にモデルの初期化や事前訓練されたネットワークの使用を指します。
一方、ファインチューニングは、転移学習されたモデルに対して追加の訓練ステップを行い、ターゲットタスクにより密接に適合させるプロセスです。
数学的に説明すると、モデルMが与えられたとき、元のタスクで学習したパラメーθsを新しいタスクのパラメータθTへと適応させるプロセスを考えます。
この適応は以下の損失関数を最小化することで行われます:
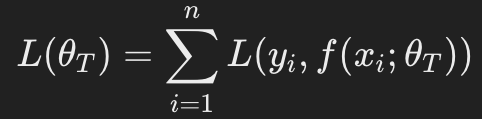
ここで、Lは損失関数、fはモデルの出力関数、(xi,yi)はターゲットタスクのデータポイントです。
転移学習の代表的なアーキテクチャと手法
転移学習は、どのようなモデル構造や学習手法を用いるかによって効果が大きく異なります。
ここでは代表的なアーキテクチャとその手法を紹介します。
1. 固定特徴抽出(Feature Extraction)
事前学習済みのモデルの一部(通常は畳み込み層などの低次特徴抽出層)を固定し、新しいタスクに合わせて分類層などの後段だけを学習させる方法です。
# PyTorchの例(特徴抽出層を固定)
for param in model.features.parameters():
param.requires_grad = False この方法は高速に訓練でき、過学習のリスクも抑えられるため、データが少ない場合に特に有効です。
2. ファインチューニング(Fine-Tuning)
事前学習済みモデルのすべて、または一部の層の重みを更新対象に含めて再学習する手法です。ターゲットタスクの特性をモデルにしっかり反映させることができますが、慎重なハイパーパラメータ調整が求められます。
たとえば、学習率(learning rate)を事前学習済み層と新規層で分けて調整するなど、工夫が必要です。
3. トランスフォーマーベースの事前学習と転移
近年では、BERT、GPT、ViTなどトランスフォーマーアーキテクチャが主流となっています。
これらは自己教師あり学習(self-supervised learning)を活用し、膨大なコーパスから知識を抽出しており、転移性能が極めて高いです。
特にNLPでは、BERTをベースとした日本語モデル(cl-tohoku/bert-base-japaneseなど)を微調整することで、高精度な日本語処理が可能です。
転移学習に適したライブラリ・ツール
実際に転移学習を活用するためのフレームワークやツールも整備されています。
以下は主要なライブラリの一部です。
- PyTorch / torchvision: 事前学習済みCNN(ResNet, VGG, MobileNetなど)を容易に再利用可能
- TensorFlow / Keras: モデルのレイヤー単位での凍結や再訓練が簡単に実装可能
- Hugging Face Transformers: NLPモデル(BERT, GPT, T5など)をファインチューニングするための標準ツール
- fastai: 転移学習を前提に設計された高レベルAPIで、初心者にも扱いやすい
これらのツールはGitHubなどで豊富なチュートリアルが公開されており、転移学習の実装ハードルを大きく下げています。
転移学習が使われる例
- 画像認識:事前に大量の画像で訓練されたネットワークを、特定の物体認識タスクに転用します。
- 自然言語処理(NLP):一般的な言語モデルを基に、特定の言語タスク(例えば感情分析)にファインチューニングします。
- 医療画像分析:公開データセットで訓練されたモデルを使用して、新たな医療画像データセットの解析に応用します。
- 音声認識:一般的な音声データで学習したモデルを、特定のアクセントや言語の音声認識に適用します。
- 異常検出:さまざまなセンサーデータに基づく異常検出システムで、一般的なデータセットで訓練されたモデルを使用し、特定の環境下での異常を識別します。
産業応用における転移学習の実例
転移学習は研究領域だけでなく、実ビジネスの現場でも積極的に導入されています。
以下に分野別の事例を紹介します。
製造業
工場の異常検知において、ある工場の設備センサーデータで訓練したモデルを、別工場に転用する事例があります。
特に、深層オートエンコーダを使った異常スコアの転移が有効です。
小売・物流
需要予測において、複数地域の販売履歴をベースにしたモデルを、データの少ない新規店舗の需要予測に応用することで、在庫最適化が実現されます。
教育分野
学習者の行動ログを分析するエドテック領域でも、転移学習により、他校で構築された行動予測モデルを別の教育機関に再利用する試みが進んでいます。
転移学習の利点と注意点
転移学習が近年注目を集める理由の一つに、限られたデータでも高精度なモデルを構築できるという利点があります。
特に医療や製造業など、データ収集にコストや時間がかかる分野では、転移学習によって大幅な効率化が可能です。
例えば、ある種類の医療画像(例:胸部X線)で訓練されたモデルの初期層を、別の種類の画像(例:MRI)解析に活用することで、ゼロから訓練するよりもはるかに少ないデータで同等の性能を達成できます。
また、転移学習は計算資源の節約にも貢献します。
大規模な事前学習モデル(例:ResNet、BERTなど)は数百時間に及ぶGPU訓練を必要としますが、これらを活用すれば小規模なGPU環境でも目的タスクに対応可能です。
ドメインの違いによる転移の難易度
一方で、転移学習には注意点も存在します。
特にソースドメインとターゲットドメインの乖離(ドメインギャップ)が大きい場合、性能が著しく低下することがあります。
たとえば、英語のニュース記事で事前学習された言語モデルを、日本語の口語会話分析にそのまま適用するのは困難です。
言語、スタイル、構造が異なるため、知識の転移がうまくいかず、逆にパフォーマンスが悪化することすらあります(この現象はネガティブトランスファーと呼ばれます)。
そのため、転移学習を実施する際は、ソースとターゲットのタスクやデータ分布の類似性をよく分析し、必要に応じて中間タスクを挟む「段階的転移(ステージドトランスファー)」の導入なども検討されます。
最近の研究動向
近年では、転移学習の発展形としてマルチタスク学習やメタ学習との組み合わせも活発に研究されています。
これらは、より柔軟に複数のタスク間で知識を共有・適応できるよう設計されており、汎用AIの実現に近づく重要なステップと見なされています。
また、大規模事前学習モデル(例:GPT、T5、CLIPなど)の登場により、「ゼロショット学習」や「数ショット学習」も現実的になっており、転移学習の適用範囲は今後さらに拡大することが期待されます。
まとめ
転移学習は、モデルの訓練時間の短縮とデータリソースの有効活用に寄与するため、AIの実用化において欠かせない技術です。特にデータが限られている場合において、転移学習は有効な手段となり得ます。
これにより、様々な分野での応用が期待される技術であり、私もタスクによって使用をしておりますが、今後の発展が楽しみです。