近年のトップダウン型AIの社会進出に伴い、AIソリューションの一つともなっている「物体検知」も幅広い業界で使用され始めています。
そこで今回は、その「物体検知技術」について、初心者にもわかりやすくまとめていきます。
物体検知の基本

物体検出とは、AIにおける画像認識技術の一種で、画像や動画中の物体のインスタンスを見つけるためのコンピュータビジョン技術になります。
物体検出アルゴリズムは、通常、機械学習やディープラーニングを活用して意味のある結果を生成します。
人間は画像や映像を見るとき、一瞬のうちに興味のあるオブジェクトを認識し、その位置を特定することができ、物体検出の目標は、この知能をコンピュータで再現することになります。
現実世界では物体検出は、自動車が走行車線を検出したり、歩行者を検出したりして、交通安全を向上させる先進運転支援システム(ADAS)を支える重要な技術であり、ビデオ監視や画像検索システムなどにも応用されています。
最新の物体検知技術とその進化
物体検知技術は日々進化しており、特に深層学習の登場により、その精度は飛躍的に向上しています。
畳み込みニューラルネットワーク (CNN) をベースにしたYoloは高精度かつ処理と学習の速さ、そしてデータの揃えやすさから、物体検知のための代表的なモデルとして広く知られています。
You Only Look Once(Yolo)は、リアルタイムオブジェクト検出アルゴリズムです。YOLO(You Look Only Once)の名前通り、このアルゴリズムでは検出窓をスライドさせるような仕組みを用いず、画像を一度CNNに通すことで、オブジェクトを検出することができ、物体検知技術の開発において非常に有効な手段となっています。
以下はYoloのメリットになります。
- 非常に高速:複雑なパイプライン不要。CNNのみ。
- 予測時に画像全体についてグローバルに推論:画像全体を見るため、クラスに関する文脈情報(周辺情報)を暗黙にエンコード。
→ 画像内の背景を物体と誤認識する可能性が低下 - 汎化性能向上:新しいデータや予期せぬ入力に適用された場合でも影響を受けにくい
You Only Look Once(Yolo)の構成は以下のようになっています。
1. 主要な構成要素
YOLOはCNNベースのアーキテクチャを採用しており、画像から特徴を捉えるために複数の畳み込み層を用い、その後、物体の位置と確率を推測するために全結合層を組み込んでいます。
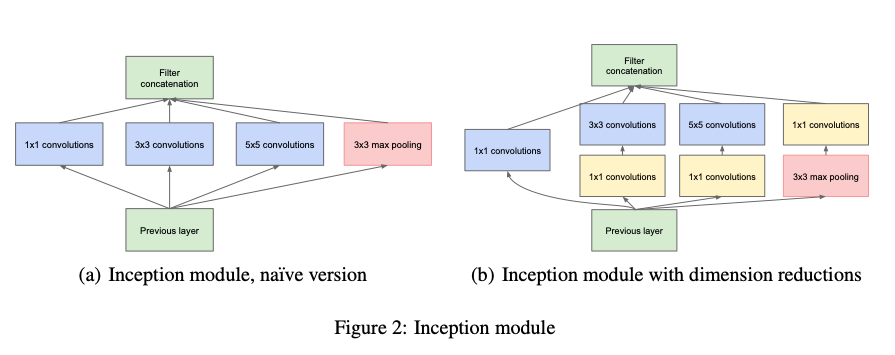
このネットワーク設計は、画像分類向けのGoogLeNetモデルから影響を受けていますが、24層の畳み込み層に続いて2層の全結合層を有し、GoogLeNetのインセプションモジュールを使用する代わりに、シンプルな1×1の畳み込みの後に3×3の畳み込みを適用する点では異なります。
2. インセプションモジュールとは
インセプションモジュールは、1×1、3×3、5×5などの異なるサイズのフィルターを持つ複数の畳み込み層を並列に配置することで構成されています。
この設計により、さまざまなスケールでの特徴抽出が可能となり、性能向上が期待できます。大きなモデルに単純に層を重ねると過学習や勾配消失の問題が生じる可能性がありますが、インセプションモジュールではこのような問題を回避しつつ効率的な計算を実現しています。
1×1の畳み込み層を介して、より大きなフィルターサイズの層に入力することで、計算コストを大幅に削減しています。
例えば、512チャネルの特徴マップに5×5フィルターを適用する場合、直接適用すると5x5x512x64で計算量は819200になりますが、1×1フィルターを間に挟むことで、(1x1x512x24)+(5x5x24x64)で計算量を50688にまで減少させることができます。
Yoloでの検知の仕組み
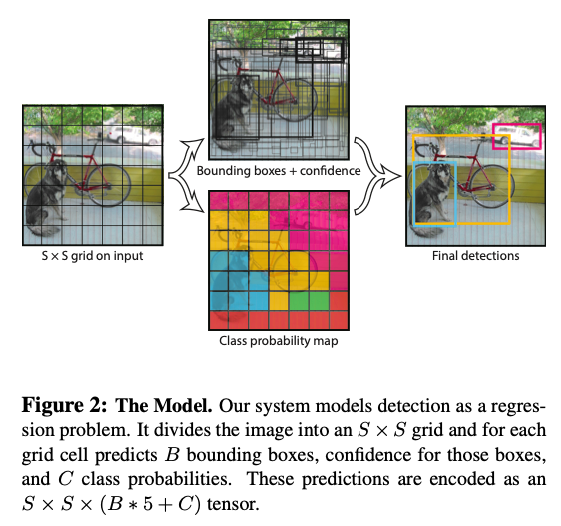
Yoloは主に以下の手順で物体を検知します。
- 画像をSxSのセルに区切る
画像内の物体の中央が特定のグリッドセルに位置する場合、そのセルが物体の識別を担当します。
- 各グリッドセルで、B個の境界ボックスとそれらの信頼度スコア(Pr(Object)*IOU)を推定
信頼度スコアは、ボックス内に物体が含まれる確率を示します。セル内に物体がない場合、信頼度は0(IOUが0のため)。存在する場合、予測ボックスと基準ボックスとの重なり(IOU)と等しい値になるように学習します。
各ボックスの予測は5つの要素(x, y, w, h, confidence)で構成され、(x, y)はグリッドセル内のボックスの中心の位置、(w)と(h)は画像全体に対して相対的なサイズを表します。
- 各グリッドセルは、C個のクラスの条件付き確率Pr(Classi|Object)も推定
ボックスはB個予測されますが、クラス確率は1つだけです。テスト時には、クラス確率と各ボックスの信頼度の積を計算します。この計算により、各ボックスに対するクラス固有の信頼度スコアが算出され、ボックスが物体にどの程度適合しているかとそのクラスに属する確率を含みます。S=7、B=2、C=20の設定では、最終的な予測は7x7x30(30=5×2+20)のテンソルになります。
IOUとは
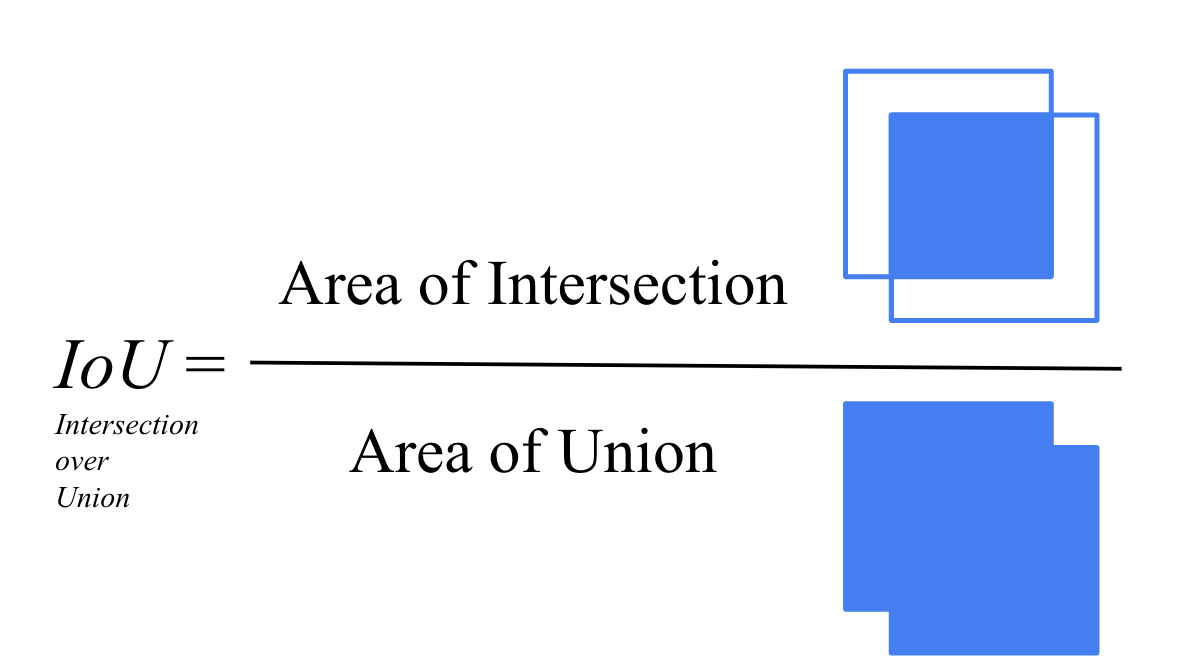
IOU(Intersection Over Union)は、オブジェクト検出タスクにおいて、予測された境界ボックスと実際の(基準)境界ボックスとの重なりを測定する指標です。IOUは、予測ボックスと基準ボックスの交差部分(Intersection)と、両ボックスの合併部分(Union)の比率で計算されます。この値は0から1の間であり、1に近いほど予測の精度が高いことを示します。オブジェクト検出モデルのパフォーマンス評価において、IOUは予測の正確性を評価するための重要な指標となります。
最新技術の動向(2025年現在)
2025年現在、物体検知の世界ではCNNをベースとしたアーキテクチャから、Transformerベースのアーキテクチャへの移行が急速に進んでいます。
中でも注目されているのが、Vision Transformer(ViT) や DETR(DEtection TRansformer) といったモデル群です。
◾️ Vision Transformer(ViT)
ViTは、画像をパッチ(小領域)に分割し、それぞれをトークンとしてTransformerで処理するという斬新なアプローチを採用しています。
これにより、CNNが苦手とする長距離の依存関係や全体の文脈把握が得意となり、従来のモデルでは見落とされがちだった微細な関係性を正確に捉えることが可能になります。
◾️ DETR(DEtection TRansformer)
DETRは、従来のアンカーやNMS(Non-Maximum Suppression)といった物体検知固有の処理を一切使わず、エンド・ツー・エンドで物体検知を実現したモデルです。
これは、物体検知の新たなパラダイムシフトとも言われており、「検出=クエリと応答」という発想により、より柔軟かつノイズに強い検出が可能になっています。
◾️ YOLOv8 / YOLO-NAS などの進化系
リアルタイム性を維持しつつ精度向上も求められる現場では、YOLOシリーズの進化形にも注目が集まっています。
YOLOv8はUltralytics社による最新版で、推論速度・精度・軽量性のバランスが抜群。
さらにNeural Architecture Search(NAS)を取り入れたYOLO-NASでは、アーキテクチャ自体をAIが自動最適化することで、人間の設計限界を超えた効率性を実現しています。
これらの技術革新により、物体検知の精度と速度はかつてないレベルに到達しており、クラウドからエッジ、さらにはオンデバイスまで応用範囲が飛躍的に広がっています。
軽量モデルとエッジ対応
現在、物体検知技術はスマートフォンやドローン、監視カメラといったエッジデバイスでのリアルタイム動作が求められる場面が急増しています。
これに応えるために重要なのが「軽量モデル」の進化です。
◾️ MobileNet-SSD:軽さとスピードの両立
MobileNet-SSDは、モバイル環境に最適化された深層学習モデルです。
Depthwise Separable Convolutionという技術を使うことで、パラメータ数を大幅に削減しながらも検出精度を維持することができます。
スマートフォンやRaspberry Piなどでも利用可能で、IoT機器と組み合わせて活用されています。
◾️ EfficientDet-Lite:スケーラブルな効率設計
Googleが開発したEfficientDetは、スケーラビリティと軽量性を兼ね備えた物体検知モデルで、EfficientNetと組み合わせることで性能とサイズのトレードオフを自在に制御できます。
Lite版では特に、TensorFlow Liteへの最適化がなされており、Androidアプリなどへの実装も容易です。
◾️ エッジ対応の設計ポイント
- モデルサイズ(MB単位):5MB以下に抑えることでオンデバイス推論が現実的に。
- 推論速度(FPS):最低でも15fps以上のリアルタイム性を確保する設計が求められます。
- ハードウェアアクセラレーション:Edge TPU(Coral)やNVIDIA Jetsonなどを活用することで処理効率を向上。
このように、軽量モデルとエッジデバイスの最適化は、持ち運べるAIの実現に不可欠なファクターであり、現場導入に直結する技術領域となっています。
データセットと評価メトリクス
高性能なモデルを構築するには、高品質なデータと公平な評価指標が必要不可欠です。
ここでは物体検知において広く使われている代表的なデータセットとメトリクスについて紹介します。
◾️ 標準データセット
- COCO(Common Objects in Context)
80種類以上の物体カテゴリを含む、日常風景中心の大規模データセット。
検出・セグメンテーション・キャプションに対応。 - PASCAL VOC
古典的だが今なお有効な20カテゴリのデータセット。
モデルの基本性能のベースラインとして使用。 - OpenImages
画像数900万枚以上、ラベル数600以上を誇る超大規模データセット。
マルチラベルや属性付き情報も豊富。
◾️ カスタムデータの構築
実運用では「特定環境・特定物体」を検出したいケースも多く、独自データセットを作成する必要があります。
以下のようなツールが役立ちます:
- LabelImg:シンプルなバウンディングボックスアノテーションツール(Pythonベース)。
- Roboflow:Webベースで画像のアップロード・アノテーション・前処理・拡張・学習用フォーマット出力まで可能な万能プラットフォーム。
◾️ 評価指標
- mAP(mean Average Precision):
検出結果の正確さを総合的に評価。
IOU(Intersection over Union)との併用で、物体位置とカテゴリの整合性を確認。 - IOU閾値:
通常は0.5(50%)以上が正解とされるが、応用によって0.75以上の厳密評価が求められる場合も。
これらを活用することで、モデルの信頼性や改善ポイントを定量的に把握でき、継続的な性能向上が可能となります。
技術実装のステップと考慮点
物体検知モデルの開発は、単なる学習だけでは終わりません。
データ準備から運用まで、多くのステップと工夫が必要です。
① データ収集とアノテーション
- 実運用において最も重要かつ時間がかかる工程。
- 多様な角度、照明、背景、天候条件などの「変化に強いデータ」を意識して収集する。
- アノテーションは可能な限り複数人でクロスチェックし、ラベルの揺らぎを排除。
② モデル選定
- 処理速度優先:YOLOv7/YOLOv8、YOLO-NAS
- 精度優先/グローバル文脈理解:DETR, ViT
- モバイル/IoT用途:MobileNet-SSD, EfficientDet-Lite
タスクに応じて選択肢は大きく変わります。
推論速度(FPS)・メモリ制約・設置環境を踏まえて最適化しましょう。
③ 学習とFine-tuning
- 事前学習済みモデルをベースに転移学習するのが一般的。
- データ拡張(回転、明るさ変更、スケーリング、ノイズ付加)で学習データを水増しして汎化性能を向上。
- 過学習を防ぐため、Early Stoppingや学習率調整も重要。
④ 推論と最適化
- 学習済みモデルをONNX形式に変換 → TensorRTやOpenVINOで高速化。
- Edge TPUやNVIDIA Jetsonへデプロイする際は、INT8量子化などの軽量化も有効。
⑤ 性能評価と継続的改善
- 学習後にはmAP、FPS、検出漏れ率、誤検出率を定期的にチェック。
- 本番環境と開発環境でのデータ差分(Domain Gap)が発生しないよう、継続的なデータ再学習やオンライン学習も視野に。
実際の事例紹介
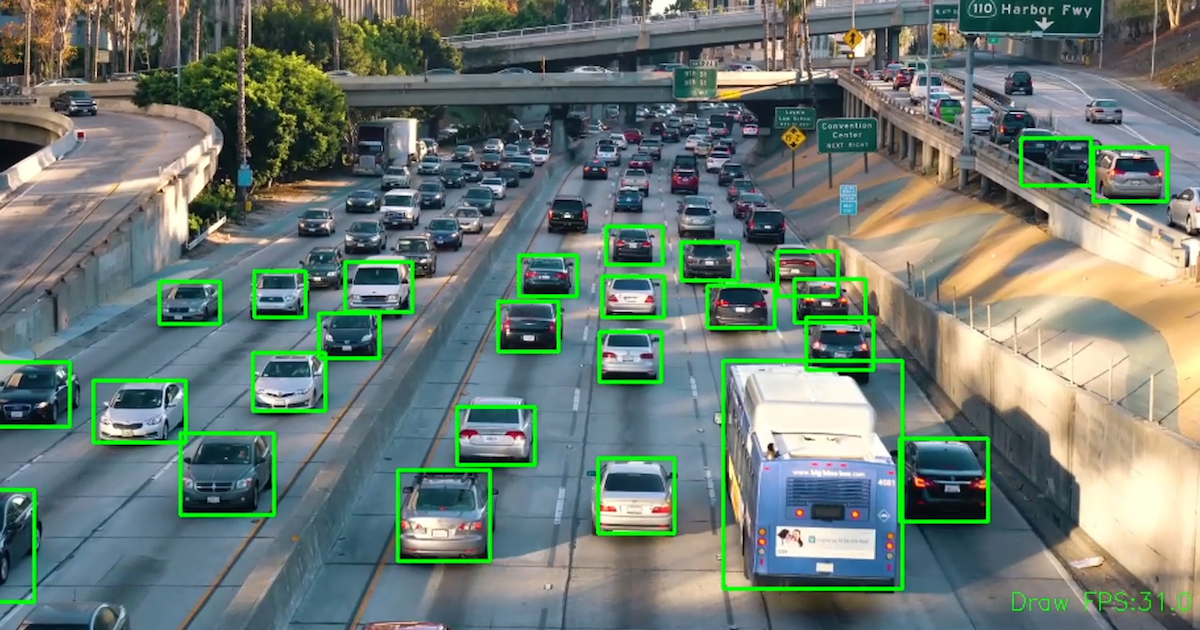
物対検知は現在様々な箇所で使用されています。
ここではいくつか代表例を挙げていきます。
1.テーマパークなど娯楽施設での群衆分析(来場者数分析や監視カメラなど)
2.自動車産業などでの物品の識別
3.飲食業界での検知(自動洗浄機に入れる際に事前に異物が含まれていないかチェックをする)
まとめ
このように物体検知技術は、多岐にわたる分野での活用事例があります。
日常生活の至るところでも物体検知が使われているところもあり、これからもどんどん世の中に進出をしてくるであろうと考えています。
超人気アニメ「ソード・アート・オンライン」の映画で出てきた「オーグマー」のようなウェアラブル・マルチデバイスもそのうち登場するかもしれません。
オーグマーはARと画像認識技術と物体検知システムの組み合わせでできたものですが、現時点でのAI開発の成長スピードとその他技術の発展速度を見るとそう遠くない未来に、このようなシステムも実現されるのではないかと考えています。
筆者である私も、実際に作成したことがありますので、この記事で興味が湧いた方はぜひ下記リンクからご覧いただければ幸いです!
URL: https://qiita.com/irohas_gawr/items/4ff5aa8c85f25915d6d2