1. まず結論:キャンセルが効かない“3大原因”
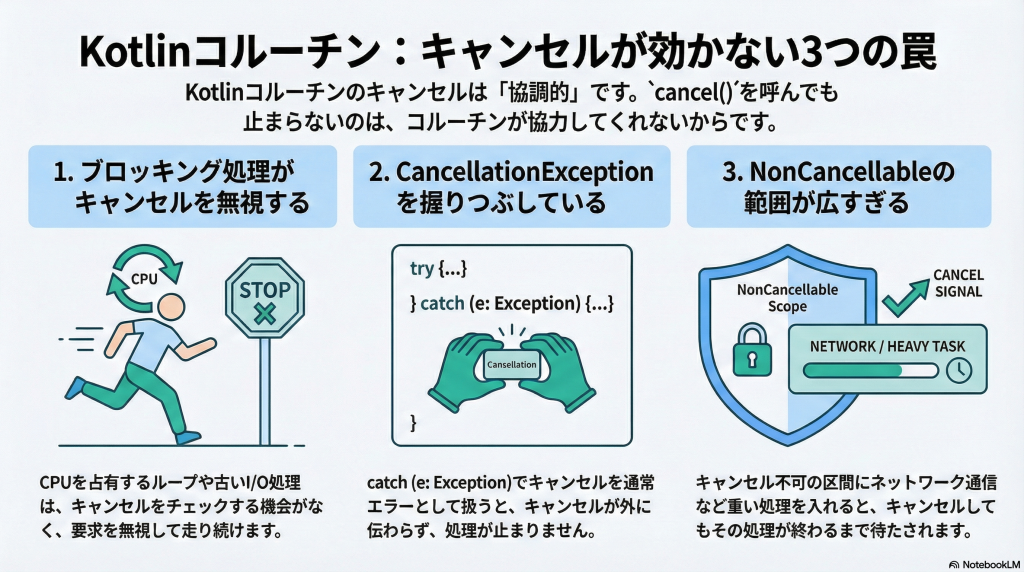
先に結論を書いてしまうと、Kotlin Coroutinesで「cancel したのに止まらない」の原因は、ほとんど次の3つに当てはまります。
1-1. 協調キャンセルできない処理(ブロッキングI/O / 無限ループ / Thread.sleep)
- ひたすらCPUを回すループ
Thread.sleepなどのブロッキングな待ち- キャンセルに対応していないDB/HTTPクライアント
このような処理は、コルーチンのキャンセルフラグを見に行かないため、cancel() を呼んでも止まりません。
「サスペンドポイント(delayなど)に戻ってこない限り止まらない」とイメージすると分かりやすいです。
1-2. CancellationException を握りつぶしている
キャンセル時には CancellationException が投げられますが、これを
catch (e: Exception)runCatching { ... }でまとめて握りつぶす
といった書き方をしてしまうと、「キャンセルなのに通常エラー扱いになってリトライされる」「キャンセルが外側に伝播しない」などの症状が出ます。
1-3. NonCancellable / 重いfinallyで「止まらない区間」を広げている
withContext(NonCancellable) は「キャンセルされても絶対に実行したい処理」を書く場所ですが、ここに
- ネットワークやDBアクセス
- 数秒かかる重いクリーンアップ
を入れてしまうと、「キャンセルしたのにいつまでも戻ってこない」という状態を自分で作ってしまいます。NonCancellable は「短く・軽く」が鉄則です。
2. 仕組み編:Coroutineのキャンセルは“要求”で、止まるのは次のチェック
2-1. cancel() と join() の関係
まず、キャンセルの基本的な動きをおさらいします。
job.cancel():キャンセルフラグを立てて、「キャンセルしてほしい」と要求するだけjob.join():そのJobが完全に終わるまで(正常終了 or キャンセル)待つ
「止まらない」と感じるケースの多くは、「cancel() は投げたけど、その後どうなっているか待っていない」か、「待ってはいるが中の処理がキャンセルを見にいっていない」かのどちらかです。
val job = scope.launch {
repeat(10) { i ->
delay(1000)
println("tick $i")
}
}
// どこかでキャンセル
job.cancel()
// ここで終了を待たないと、中が完了する前に次の処理へ進むことがあります
job.join()`
このコードでは、cancel() の後に join() でしっかり待つことで、「処理が確実に止まった状態」を保証しています。スコープ内で大量のJobを管理するときは、どこまで待つのかを明確にしておくとデバッグしやすくなります。
2-2. サスペンドポイントで止まる(delay / yield / ensureActive)
Coroutine は、次のようなタイミングでキャンセルに気づきます。
delayのようなサスペンド関数に戻ってきたときyieldで明示的に他の処理に譲ったときensureActive()を呼んだとき
CPUバウンドのループであれば、ループの中に yield や ensureActive を入れてあげることで、キャンセル要求に気づけるようになります。
launch {
while (isActive) {
// 重い計算...
doHeavyWorkChunk()
yield() // 他のJobに実行を譲りつつ、キャンセルもチェックする
}
}このコードでは、重い計算を小さなチャンクに分けながら yield() を挟むことで、「キャンセルされても処理が永遠に走り続けないようにする」ことを狙っています。isActive や ensureActive() を使うことでも同様の効果が得られます。
2-3. withTimeout が投げる例外と期待挙動
withTimeout は、指定時間を過ぎたら TimeoutCancellationException(CancellationException のサブクラス)を投げてキャンセルします。
try {
withTimeout(1_000) {
// ここが1秒以内に終わらないと TimeoutCancellationException
longRunningSuspend()
}
} catch (e: TimeoutCancellationException) {
// タイムアウトとして扱う
}このコードでは、withTimeout 内の処理が1秒以内に終わらない場合に、タイムアウトとして例外を投げています。TimeoutCancellationException は CancellationException の一種なので、一般的には「正常なキャンセルの一種」としてログを静かめに扱ったり、リトライポリシーから外したりすることが多いです。
3. 症状別:cancelしたのに処理が止まらない
3-1. 無限ループ/重いCPU処理の直し方
典型的な例として、次のようなループがあります。
fun CoroutineScope.launchHeavyLoop() = launch {
while (true) {
doHeavyWork() // CPUをひたすら使う処理
}
}このコードは一度走り出すと、キャンセルを投げても止まりません。
ループが一度もサスペンドしないため、キャンセルフラグを見に行く機会がないからです。
修正例は次のようになります。
fun CoroutineScope.launchHeavyLoop() = launch {
while (isActive) { // もしくは ensureActive() を中で呼ぶ
doHeavyWorkChunk() // 小さめのチャンクに分割する
yield() // キャンセルチェック+他のコルーチンに譲る
}
}このコードでは、ループ条件に isActive を使い、かつ yield() を挟むことで、「キャンセルされたらループから抜ける」ようにしています。また、doHeavyWork() を doHeavyWorkChunk() に分割して、小さな単位でキャンセルできるようにしているところがポイントです。
3-2. ブロッキングI/Oが混ざっている見分け方
「ログを仕込んでも、特定の行から先のログが一切出ない」という場合、多くはブロッキングI/Oで止まっています。
- 自前で
Thread.sleepを使っていないか - 昔のライブラリ(JDBCの同期API、レガシーHTTPクライアントなど)を使っていないか
- SDKが独自スレッドを持っていて、キャンセル非対応になっていないか
「この行の前にはログが出るが、後は一切出ない」という箇所を特定し、その周辺が本当にサスペンド関数かどうか、キャンセルを考慮しているAPIかどうかを確認していきます。
3-3. 対処パターン:キャンセル可能APIへ寄せる/隔離する
対処パターンは大きく2つです。
- キャンセル可能なAPIを選び直す:
- OkHttpやKtorなど、コルーチンと相性の良い非同期クライアントへ置き換える
- JDBCでも、タイムアウトや
Statement.cancel()を組み合わせるなどの工夫をする - 隔離する:
- どうしてもブロッキングな処理が残る場合は、
withContext(Dispatchers.IO)など専用スレッドに閉じ込める - タイムアウト境界をそこで切り、「この中はキャンセル不可だが、外からは時間で見切る」と割り切る
完璧にキャンセル可能にするのが難しいケースも多いので、「どこまでを協調キャンセルの対象にするか」を設計として決めておくと、迷いにくくなります。
4. 症状別:withTimeoutが効かない / 返ってこない
4-1. タイムアウトは「協調キャンセルが前提」
withTimeout は内部的にキャンセルを投げているだけなので、「中の処理がキャンセルを見ない」場合は、タイムアウトしてもすぐには止まりません。
withTimeout(1_000) {
// 悪い例:ブロッキングI/O
Thread.sleep(5_000) // ここでスレッドがブロックされる
}
println("終わった") // 1秒でここに来てほしいが、実際は5秒待たされるこのコードでは、withTimeout 自体は1秒後にキャンセル要求を出しますが、Thread.sleep がスレッドを2〜5秒ブロックしてしまうため、実際にはすぐに戻ってきません。
「withTimeout を巻けば何でも止まる」は誤解で、「中身が協調キャンセルに協力している前提」で初めて効きます。
4-2. “どこがブロッキングか”切り分ける手順
タイムアウトが効かないときは、次の順番で疑っていくと効率的です。
- DBアクセス(JDBCなど)
- HTTPクライアント(同期クライアントかどうか)
- ファイルI/O(巨大ファイルの読み書き)
- 外部SDK(クラウドSDKなど)の同期API
それぞれの前後にログを置き、「どこでログが止まるか」を確認します。
止まった箇所がサスペンド関数ではなく同期APIなら、「ここがタイムアウトのボトルネックだな」と切り分けられます。
4-3. 対処パターン:キャンセル可能APIへ寄せる or 境界を作る
基本は3章と同様で、次の二択になります。
- キャンセル可能 or タイムアウト設定があるAPIに置き換える
- どうしても置き換えられない場合、「このブロッキング処理は最大N秒まで」と別途制御する
例えば、どうしても同期DBドライバを使わないといけない場合、
- DBコネクション側のタイムアウトを設定
- アプリ側の
withTimeoutは「その外側」で使う
といった形で、層ごとにタイムアウトを設計していくことが多いです。
5. 症状別:キャンセルで落ちる / 逆に止まらない(例外処理が原因)
5-1. CancellationException は“正常系”として扱う
キャンセルに成功したときも、内部的には CancellationException がスローされます。
これは「エラー」ではなく、「キャンセルがうまく動いた」という意味なので、通常の例外と同じ扱いをするとログがうるさくなったり、無駄なリトライが走ったりします。
5-2. 悪い例:全部 catch (e: Exception) で飲む
// 悪い例
suspend fun fetchData(): Result<Data> {
return try {
val data = api.getData() // ここでキャンセルが飛んでも全部Exceptionで取られる
Result.success(data)
} catch (e: Exception) {
// CancellationExceptionもここに来てしまう
Result.failure(e)
}
}このコードでは、キャンセル時の CancellationException も通常の失敗として扱われてしまい、
呼び出し側から見ると「キャンセル」なのか「本当のエラー」なのか区別できません。
修正パターンとしては、CancellationException を明示的に再throwします。
suspend fun fetchData(): Result<Data> {
return try {
val data = api.getData()
Result.success(data)
} catch (e: CancellationException) {
// キャンセルはそのまま上に伝える
throw e
} catch (e: Exception) {
// 本当のエラーだけResult.failureに包む
Result.failure(e)
}
}このコードでは、キャンセル時の例外だけはそのまま上に伝え、その他の例外だけを Result.failure に変換しています。こうすることで、「キャンセルはキャンセルとして処理される」状態を維持しつつ、通常エラーだけをドメインロジックで扱えるようにしています。
5-3. リトライ設計:タイムアウト/キャンセルとそれ以外を分ける
自動リトライを書くときも、CancellationException 系をリトライ対象から外すのが基本です。
suspend fun <T> retryOnError(
times: Int = 3,
block: suspend () -> T
): T {
repeat(times - 1) { attempt ->
try {
return block()
} catch (e: CancellationException) {
// キャンセルは絶対にリトライしない
throw e
} catch (e: Exception) {
// ログだけ出してリトライ
println("attempt $attempt failed: $e")
}
}
// 最後の1回は例外をそのまま返す
return block()
}このコードでは、リトライ中にキャンセルが飛んだ場合は即座に外側へ伝播し、それ以外の例外だけをリトライ対象にしています。リトライロジックを書くときは、まず「キャンセルだけは別扱いにする」という癖をつけておくと安全です。
6. NonCancellableの使いどころ:finallyを安全にする最小設計
6-1. withContext(NonCancellable) の本来の目的
NonCancellable は「キャンセルされても走らせたい後処理」を書くためのコンテキストです。
withContext(Dispatchers.IO) {
try {
doSomething()
} finally {
withContext(NonCancellable) {
// ロック解放や状態フラグの更新など、必ず実行する必要がある処理
releaseLock()
}
}
}このコードでは、doSomething() 中にキャンセルされても、releaseLock() だけは必ず実行するようにしています。本来はこのように「短く・軽い後処理」を守るために使うのが想定された用途です。
6-2. やりがち事故:NonCancellable内でネットワーク/DBを叩く
一方で、次のような書き方をしてしまうと事故のもとです。
withContext(Dispatchers.IO) {
try {
doSomething()
} finally {
withContext(NonCancellable) {
// 悪い例:ここで外部I/Oをたくさんやる
api.sendLog()
db.saveCleanupHistory()
}
}
}このコードでは、キャンセル後に sendLog() や db.saveCleanupHistory() が終わるまで待つ必要があり、結果として「キャンセルしたのに戻ってこない」という状態になります。
NonCancellableを範囲広く使いすぎると、「止まらない区間」を自分で増やすことになってしまいます。
6-3. 現実解:後処理は最小+外部I/Oは別設計へ
現実的には、NonCancellableの中には次のようなものだけを残すのが安全です。
- メモリ内のフラグ更新
- ローカルなロックの解放
- タイマーのキャンセルなど、短時間で終わる処理
外部I/O(ネットワーク・DB)は、
- 別のJobに切り出して送信(ログ送信が失敗しても本体のキャンセルを遅らせない)
- そもそも「キャンセルされた後にやるべきか?」を再検討する
といった形で設計する方が、全体としては安定します。
7. Android実務:viewModelScope/lifecycleScopeで「画面破棄後も動く」を潰す
7-1. viewModelScope / lifecycleScope の寿命
Androidでは、viewModelScope と lifecycleScope を使うのが一般的です。
viewModelScope:ViewModel.onCleared()でキャンセルされます。- 画面回転など、ViewModelが破棄されるタイミングでJobも止まる想定です。
lifecycleScope:LifecycleOwnerのライフサイクルに紐づきます。- 通常は
onDestroyでキャンセルされます。
にもかかわらず「画面を閉じたのにコルーチンが動き続けている」場合、多くは別のscope(GlobalScope など)でJobを動かしてしまっています。
7-2. “動き続ける”典型パターン
// 悪い例:Repositoryの中でGlobalScopeを使う
class UserRepository {
fun fetchUserAsync(): Deferred<User> {
return GlobalScope.async {
api.fetchUser()
}
}
}このコードでは、GlobalScope に紐づくため、画面やViewModelが消えてもJobは生き続けます。
呼び出し側がキャンセルしても、内側がscopeを無視しているので「止まらない」状態になります。
修正としては、呼び出し元のscopeをちゃんと受け渡します。
class UserRepository {
fun CoroutineScope.fetchUserAsync(): Deferred<User> {
// 呼び出し側のscope(viewModelScopeなど)にぶら下げる
return async {
api.fetchUser()
}
}
}
// 呼び出し側
viewModelScope.launch {
val user = fetchUserAsync().await()
// ...
}このコードでは、Repositoryが CoroutineScope を拡張している形にして、呼び出し側のscopeにぶら下がるようにしています。こうすることで、画面破棄時に viewModelScope がキャンセルされれば、内部のAPI呼び出しも連鎖して止まるようになります。
7-3. デバッグ観点:Jobツリーとキャンセル伝播を見る
Androidで「どこかに生き残っているJob」を探すときは、
- どのscopeから
launch/asyncしているか - キャンセル時にどのログが出るか(
invokeOnCompletionなどで見る) SupervisorJobやchildの構成がどうなっているか
を意識して見ると分かりやすいです。大きめのプロジェクトでは、「新しいscopeを作るのはここだけ」というルールを決めておくと、「どこにJobの根っこがあるか」を追いやすくなります。
8. まとめ
8-1. チェックリスト:まず疑うポイント
キャンセルが効かない・おかしいと感じたときは、次の順でチェックしてみてください。
- ブロッキング処理が紛れ込んでいないか(
Thread.sleep、同期I/O、古いSDKなど) - ループや重い処理に
yield/ensureActiveを入れているか CancellationExceptionを catch-all で握りつぶしていないかwithTimeoutの中身が本当に協調キャンセル可能かNonCancellableの中に重い処理を入れていないか- Androidなら、scopeの寿命(
viewModelScope/lifecycleScope)から外れたscopeを使っていないか
8-2. 直す順番:握りつぶし → ブロッキング → NonCancellable
実務で手を付ける順番としては、
CancellationExceptionの握りつぶしをやめる(rethrowを徹底)- ブロッキング処理の洗い出し(ログとstacktraceで場所を特定)
NonCancellableの範囲を最小化(外部I/Oを追い出す)
この3つを順に直していくだけでも、「キャンセルしたのに止まらない」「タイムアウトが効かない」という問題はかなり軽減できます。
Coroutineのキャンセルはあくまで「協調的」であり、アプリ側がちゃんと協力する前提だということを頭の片隅に置いておいてください。
9. 参考リンク
- Kotlin公式:Cancellation and timeouts
https://kotlinlang.org/docs/cancellation-and-timeouts.html - kotlinx.coroutines API:withTimeout
https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/with-timeout.html - kotlinx.coroutines API:NonCancellable
https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/-non-cancellable/ - kotlinx.coroutines API:ensureActive
https://kotlinlang.org/api/kotlinx.coroutines/kotlinx-coroutines-core/kotlinx.coroutines/ensure-active.html - Android Developers:Coroutines(lifecycleScope 等)
https://developer.android.com/topic/libraries/architecture/coroutines



